ในยุคปัจจุบันปัญญาประดิษฐ์ (AI) กลายเป็นเทคโนโลยีสำคัญที่ขับเคลื่อนการเปลี่ยนแปลงในหลากหลายอุตสาหกรรม หนึ่งในสาขา AI ที่น่าจับตามองคือ Generative AI (Gen AI) หรือ AI ที่สามารถสร้างเนื้อหาใหม่ ๆ เช่น ข้อความ รูปภาพ เสียง หรือวิดีโอ แต่ก่อนที่จะเริ่มสร้าง Gen AI ที่น่าทึ่งเราจำเป็นต้องเข้าใจพื้นฐานสำคัญอย่าง Vector Embeddings
Vector Embeddings คืออะไร ?
Vector Embeddings เป็นเทคนิคการแปลงข้อมูล เช่น ข้อความ รูปภาพ และวิดีโอ ให้เป็นเวกเตอร์ (Vector) ซึ่งเป็นชุดตัวเลขที่แทนความหมายของข้อมูลนั้น โดยส่วนใหญ่จะใช้แปลงข้อความเป็นเวกเตอร์มากกว่า ซึ่งมักเรียกว่า Text Embeddings
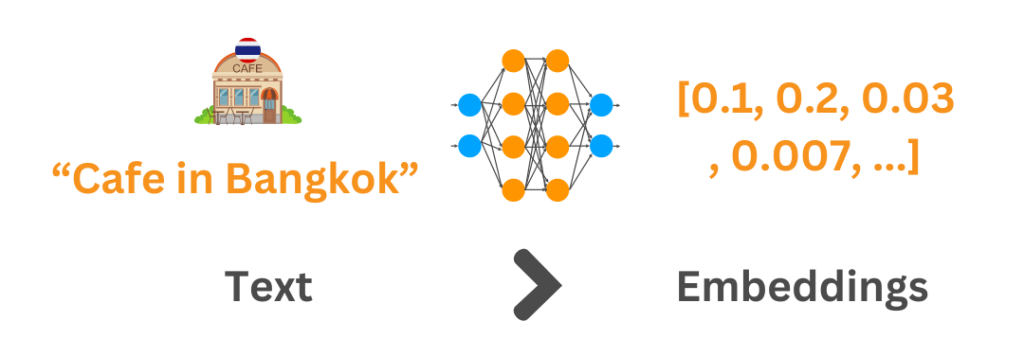
แต่ก่อนที่จะลงลึกกับ Embeddings ไปมากกว่านี้ ผมอยากพาทุกคนไปจินตนาการถึงแชลเลนจ์ต่าง ๆ ที่เวลาจะใช้เทคโนโลยี Generative กับองค์กรของตนมักจะมีคำถามต่าง ๆ อาทิ
- เราจะเอา LLMs ไปใส่ใน Chatbots หรือระบบ Search ที่เป็นข้อมูลขององค์กรได้อย่างไร ?
- เรามีสินค้าต่าง ๆ อยู่เป็นหมื่น ๆ ชิ้น จะให้ LLMs จดจำอย่างแม่นยำได้อย่างไร ?
- หรือเราจะให้ LLMs ช่วยแนะนำสินค้าของเราอย่างไร ?
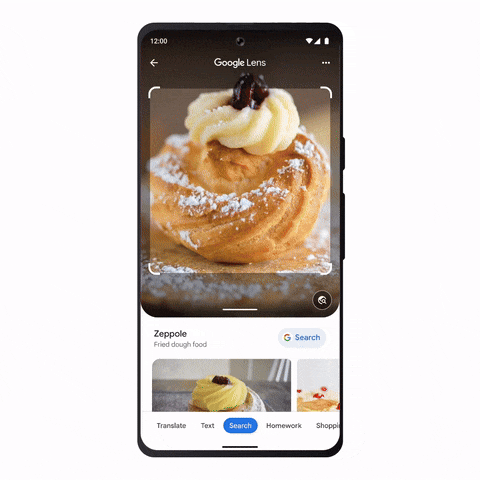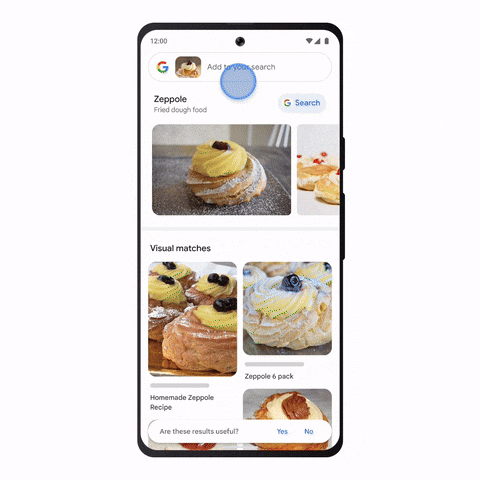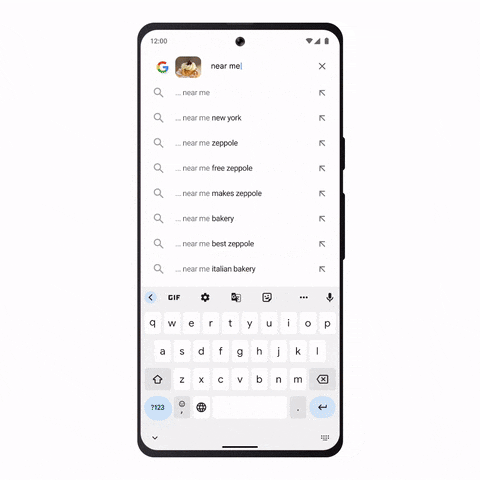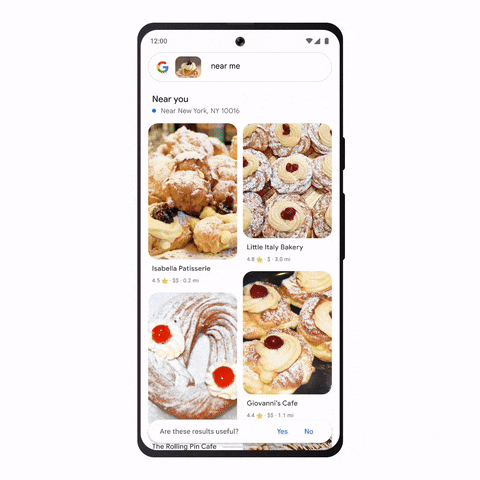
มาลองดูตัวอย่างนี้บนเว็บไซต์ ai-demos.dev จาก Google กันครับ
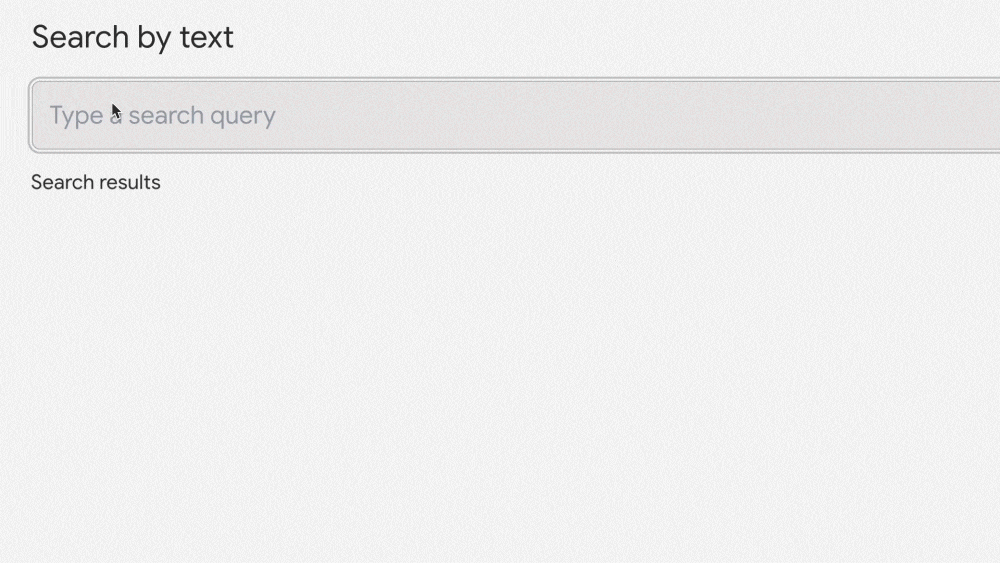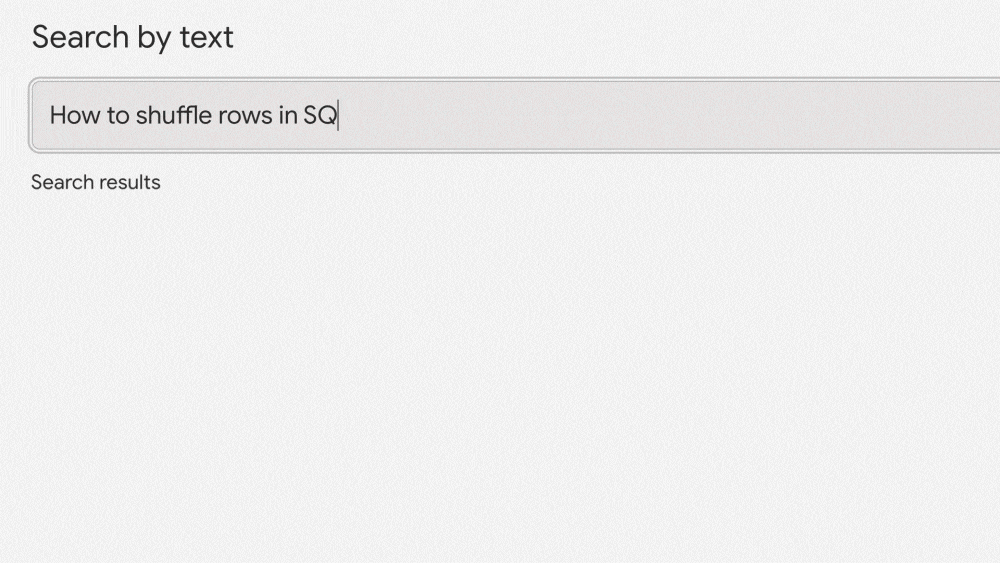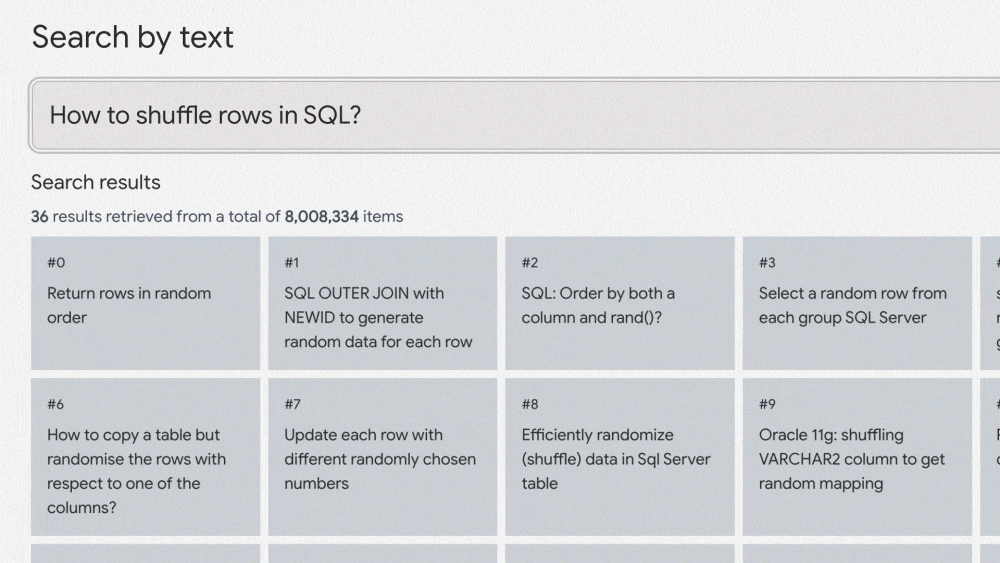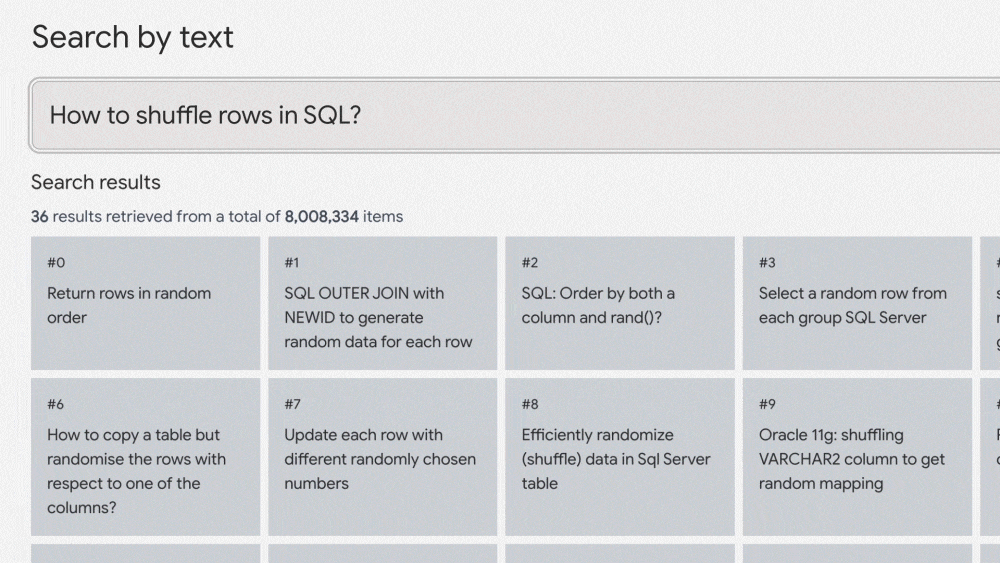
ตัวอย่างข้างต้นจะเป็นการค้นหาด้วยข้อความและได้ผลลัพธ์เป็นกระทู้ที่เกี่ยวข้องบน Stackoverflow กว่า 8 ล้านคำถาม และตอบกลับมาภายในไม่กี่ Milliseconds
สิ่งที่น่าสนใจของตัวอย่างนี้คือ
- Semantic Search : การค้นหาด้วยคำถามไม่ใช่คีย์เวิร์ด ซึ่งตัว LLMs จะเข้าใจความหมาย ความต้องการ (Semantics) และนำผลลัพธ์มาตอบได้สัมพันธ์กัน แม้ว่าจะไม่ได้มีคีย์เวิร์ดที่ตรงกับเอกสารนั้น ๆ เลยก็ตาม
- Grounding LLMs : เนื่องจาก LLMs ไม่ใช่ Database ซึ่งการจดจำสิ่งต่าง ๆ ขององค์กรมีการเพิ่มจำนวนมากอาจทำให้ LLM มีผลกระทบต่อหน่วยความจำทำให้เกิด Hallucinations ซึ่งการใช้เทคนิค Grounding เปรียบเสมือน Attach Stackoverflow Dataset ข้างต้นเป็น External Memory โดยไม่ต้องจดจำกระทู้คำถามกว่า 8 ล้านเรื่อง และตอบกลับได้อย่างรวดเร็วในระดับ Millisecond ด้วย Vector Search ซึ่งในทางปฏิบัติจริงการตั้งเครื่องประมวลผลเอง หากออกแบบมาไม่ครอบคลุมหรือ Resource ไม่เพียงพอ อาจจะทำให้ใช้เวลาค้นหานานมาก ๆ ซึ่งผมจะอธิบายเทคโนโลยีนี้ในหัวข้อถัด ๆ ไปครับ
ผู้อ่านสามารถลองเล่นได้ที่ ai-demos.dev เพื่อลองดูการค้นหาแบบอื่น ๆ เช่น ค้นหารูปภาพด้วยข้อความ หรือค้นหารูปภาพด้วยรูปภาพก็ได้ ซึ่งเบื้องหลังก็คือ Vector Search ครับ
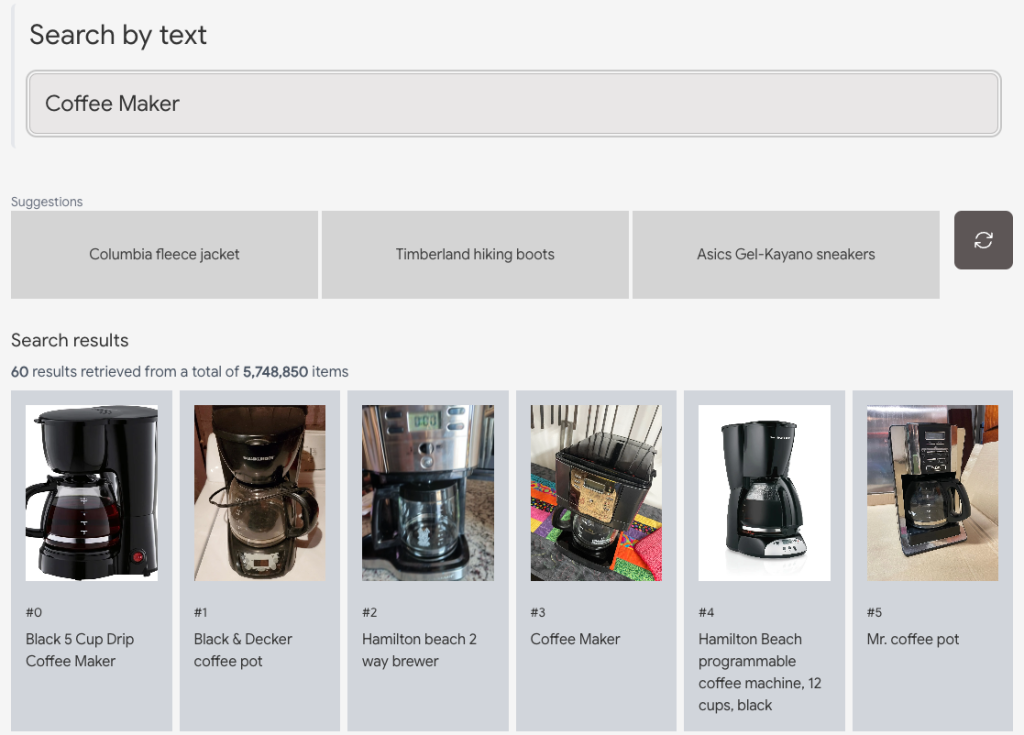
Vector คืออะไร ?
ทีนี้เมื่อผู้อ่านพอจะเห็น Use-cases ของ Vector Search กันแล้ว คงจะเกิดคำถามในใจว่า Vector คืออะไร ? ทำไมชื่อคุ้น ๆ
ใช่แล้วครับ Vector ตัวนี้เป็นตัวเดียวกับที่เราเคยได้เรียนในช่วงมัธยม หมายถึงปริมาณทางคณิตศาสตร์ที่มีขนาด (Magnitude) และทิศทาง (Direction) เช่น ความเร็วในทางฟิสิกส์ นั่นแปลว่าสิ่งที่เราเรียนทั้งหมดในวันนั้น จะมาใช้กับงานด้าน AI ในวันนี้ครับ
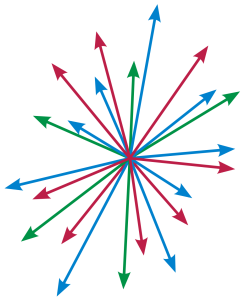
ตัวอย่างแบบจำลองเวกเตอร์หลายทิศทางจาก Wikipedia
Vector กับ Machine Learning เกี่ยวข้องกันอย่างไร ?
ประการแรกเลยคือ Machine Learning นั้นเรียนรู้จากข้อมูล และข้อมูลมักจะอยู่ในรูปแบบ Vector ดังนั้น Vector ช่วยให้ Machine Learning เข้าใจความสัมพันธ์ระหว่างข้อมูล
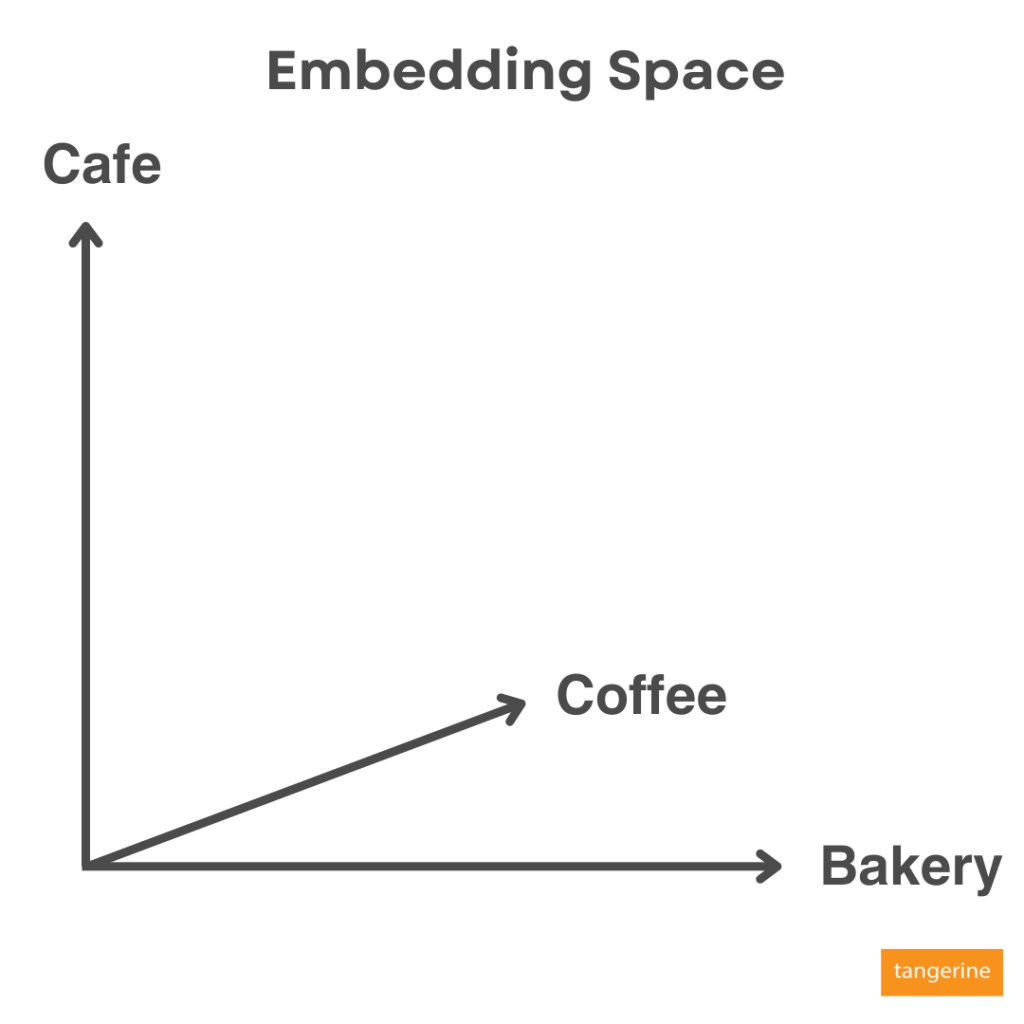
ตัวอย่างเช่น เรามี AI ตัวหนึ่งที่ Train โมเดลภาษามาเรียบร้อยพร้อมที่จะ Embed พวกข้อมูลต่าง ๆ เช่น ข้อความหรือรูปภาพ เจ้าตัว AI จะสร้าง Space ขึ้นมาเรียกว่า Embedding Space ที่มีความสัมพันธ์กันของมิติ (Dimension) ต่าง ๆ
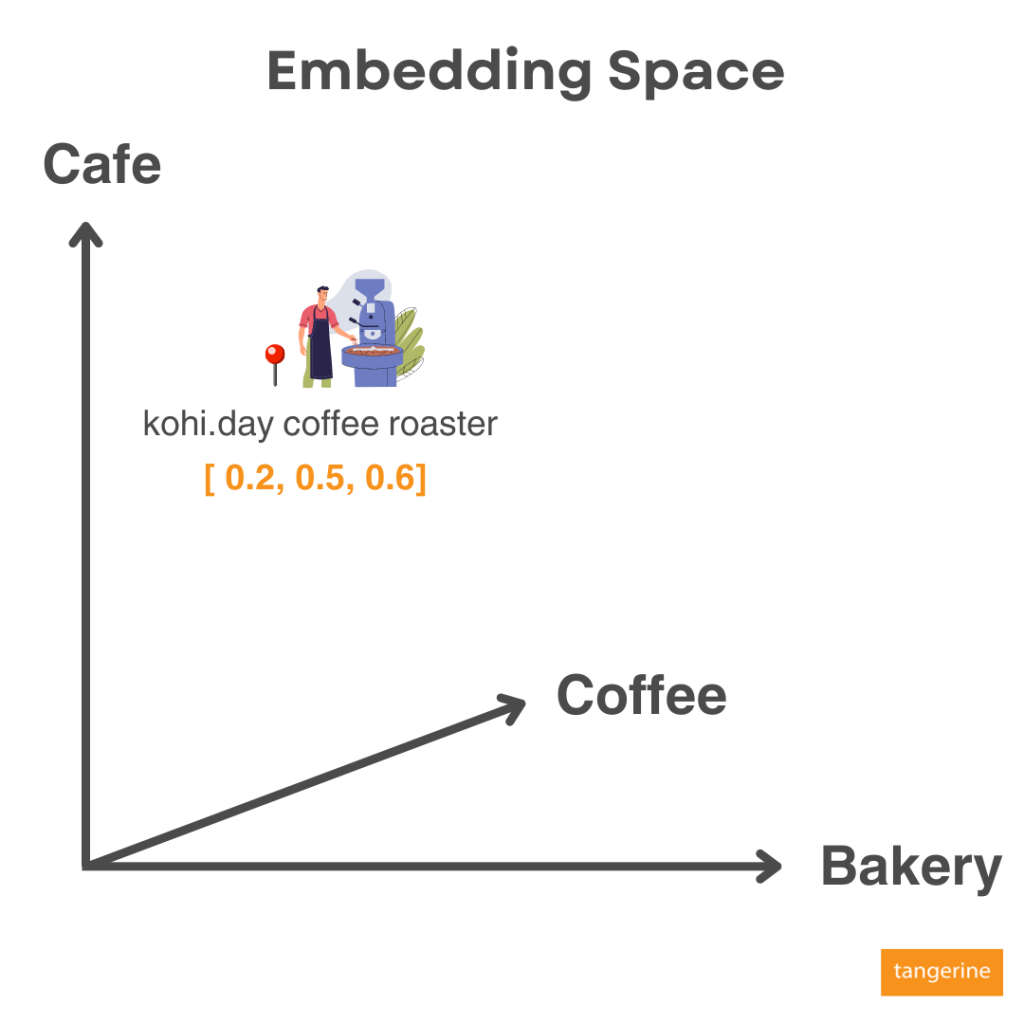
หลังจาก Embeddings ข้อมูลของเรา มันก็จะทราบตำแหน่งว่าข้อมูลของเราไปอยู่ตรงไหนของ Embedding Space นี้ เช่น คำว่า kohi.day coffee roaster จะมีความใกล้เคียงกับกลุ่ม Cafe, Coffee, Bakery โดยมีสัดส่วนที่ 20%, 50% และ 60% ตามลำดับ ซึ่งแสดงเป็นค่า Embeddings เป็น 0.2, 0.5 และ 0.6 ใน Dimensional space หรือมิติความสัมพันธ์นี้
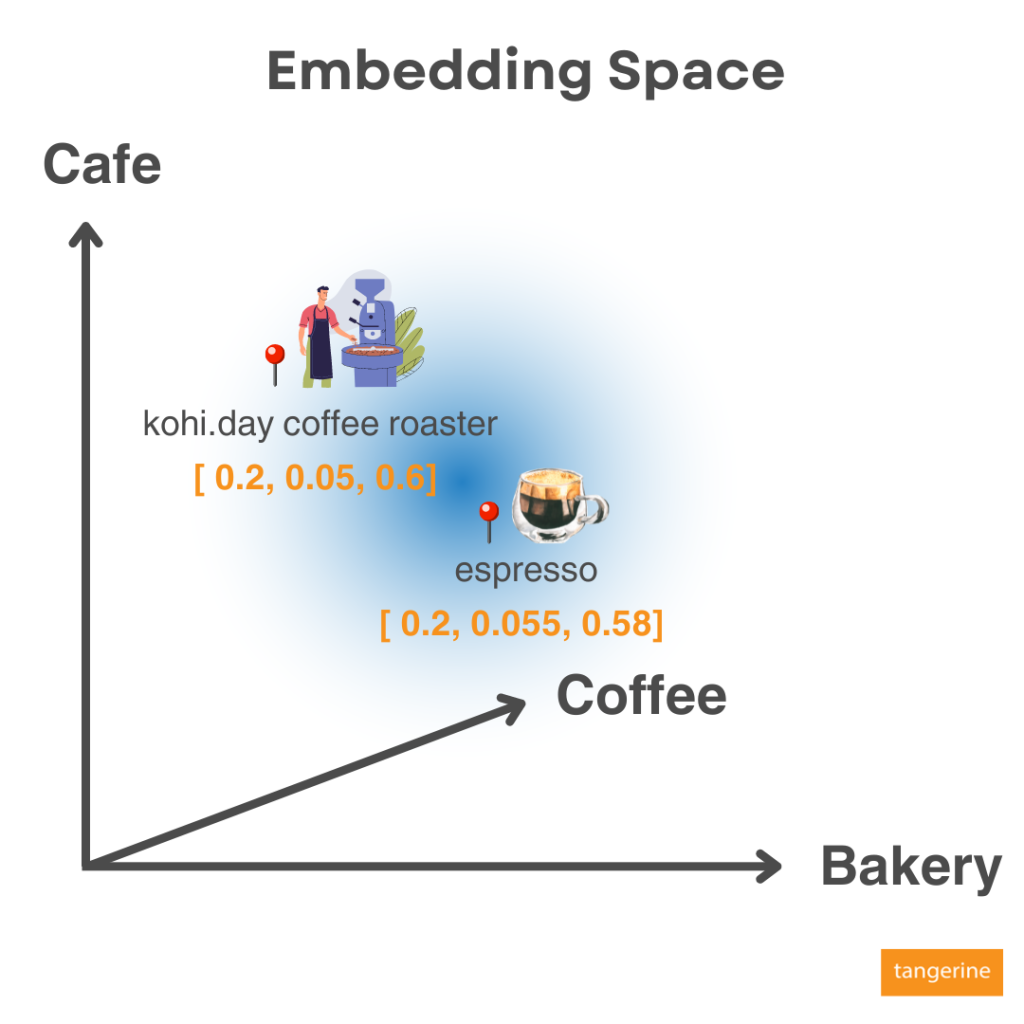
หลังจากนั้นเมื่อมีข้อมูลใหม่ที่ถูก Embeddings ก็จะถูกจัดลงตำแหน่งบน Embedding Space เช่นกัน เนื้อหาที่มีข้อมูลคล้ายกันก็จะอยู่ใกล้กัน ทำให้เมื่อข้อมูลทั้งหลายถูก Embed เป็น Vector ก็จะหาความสัมพันธ์กันไม่ว่าจะใกล้หรือไกล จึงสามารถทำ Use-cases เช่น Product Recommendation หรือ ภาพยนตร์ที่เนื้อหาคล้ายกันบนแพลตฟอร์มภาพยนตร์ได้
ดังนั้นบริการของ Google ส่วนใหญ่ที่มีการแสดงผลลัพธ์หรือการแนะนำ (Recommendations) กับข้อมูลที่เกี่ยวข้องต่าง ๆ เช่น Google Search, Youtube, Play Store มีเทคนิคพื้นฐานมาจากสิ่งเหล่านี้
แม้กระทั่ง Google Lens เองที่ยกมือถือใช้กล้องส่องก็ได้ผลลัพธ์แล้ว ก็มีความเป็น Image Search เช่นกัน เราสามารถใช้ Image ที่ Crop แล้วนำเข้า Embedding Model เพื่อค้นหารูปภาพหรือผลิตภัณฑ์ที่ใกล้เคียงบน Embedding Space ซึ่งจะได้ผลลัพธ์ออกมาเป็นสินค้าที่คล้ายกันได้
ในมุม Embeddings จึงเป็นพื้นฐานที่นำไปต่อยอดในหลากหลาย Use-cases ยอดนิยมดังนี้ครับ
- Recommendation Systems : การแนะนำภาพยนตร์ หรือ แนะนำสินค้าชิ้นถัดไปที่จะซื้อ
- Search : ลักษณะเดียวกับ Google Search ทั้งข้อความและรูปภาพ
- Chatbot : ที่สามารถถาม-ตอบได้
- Incident Classification : ตรวจจับ Incident แยกแยะแต่ละ Issue และจัด Priority
- Data Preprocessing : การเตรียมข้อมูลก่อนป้อนเข้า Machine Learning Model
- Fraud Detection : ตรวจจับข้อมูลทุจริต หรือมักใช้ในระบบความปลอดภัย
- Typo Detection : ตรวจจับการพิมพ์ผิด หรือคำที่คลุมเครือ หรือความหมายใกล้เคียง
- Model Monitoring : ตรวจจับว่าโมเดลเรามีการ Drift ควรที่จะ Re-training แล้วหรือไม่
ดังนั้น Embeddings จึงมีความสำคัญมาก ๆ ในการสร้างปฏิสัมพันธ์ระหว่างมนุษย์กับคอมพิวเตอร์ที่เรียกว่า Human Computer Interaction
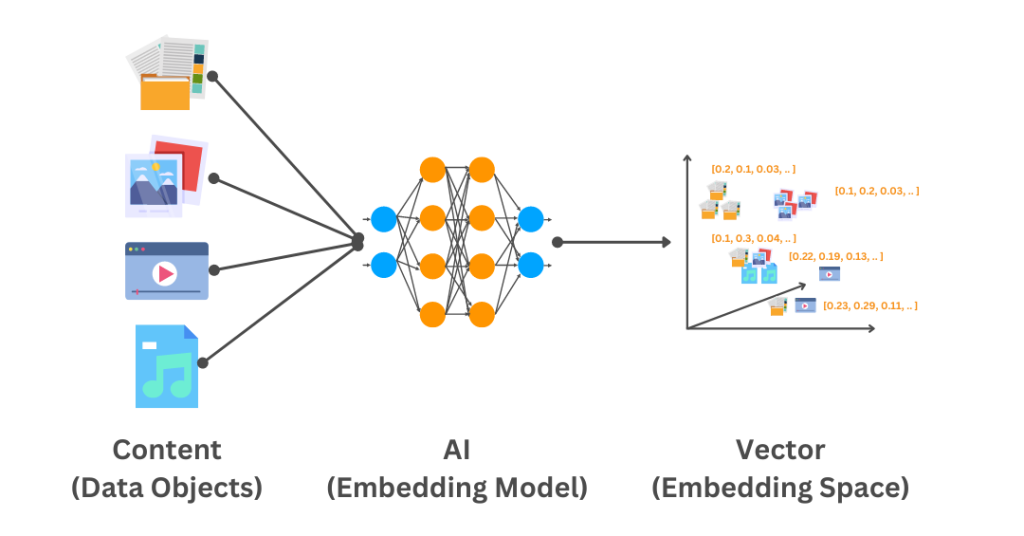
ทำไม Vector Embeddings ถึงสำคัญสำหรับ Gen AI?
Gen AI จำเป็นต้องเข้าใจความหมายของข้อความที่เราถามเพื่อสร้างเนื้อหาที่ถูกต้องและเกี่ยวข้องกัน ดังนั้น Vector Embeddings จะช่วยทำให้ Gen AI
- มีความเข้าใจความหมายของคำและวลีต่าง ๆ
- เรียนรู้ถึงความสัมพันธ์ระหว่างคำหรือข้อมูล
- สร้างเนื้อหาใหม่ที่มีความหลากหลายและน่าสนใจ
ดังนั้น Embeddings จึงมีความสำคัญมาก มีตัวอย่างหนึ่งที่ทำให้ผู้อ่านเข้าใจ Embedding Space ได้มากขึ้นที่ทาง Nomic AI ทำ Platform ที่ชื่อว่า Atlas สำหรับแสดงความสัมพันธ์บน Embedding Space ในการแสดงข้อมูลของคำถามบน Stackoverflow กว่า 8 ล้านคำถาม เช่นเดียวกับตัวอย่าง Search บน Vector Search ข้างต้น สามารถเข้าผ่านลิงก์นี้ครับ

ถ้าเราขยายเข้าไปข้างในจะเห็นแต่ละหัวข้อ แต่ละ Node ที่มีเนื้อหาใกล้กันก็จะอยู่ใกล้ศูนย์กลางของแต่ละหัวข้อ เช่นตัวอย่างนี้จะเป็นหัวข้อ Installing Python Packages เมื่อนำ Cursor ไปวางก็จะเห็นรายละเอียดบน Node นั้นครับ ซึ่ง Node ก็แทน Content ในคำถามนั้น ๆ บน Stackoverflow
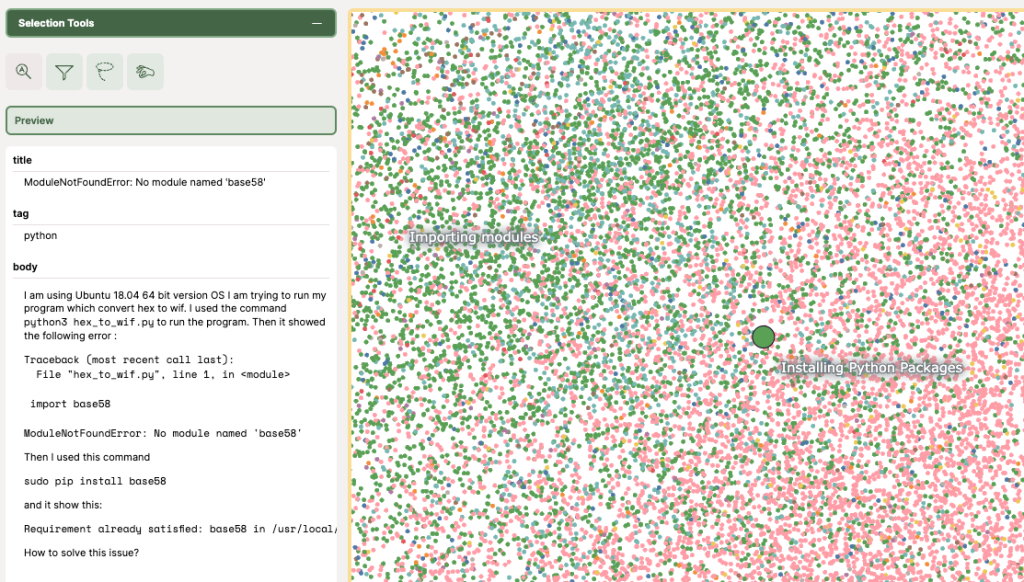
ทีนี้สมมติว่าเราจะ Query คำถามเราแม้ว่าชื่อหัวข้อจะไม่ตรงกับแต่ละ Node เป๊ะ ๆ แต่ด้วยการ Embeddings เป็น Vector ก็ทำให้ Query หรือคำถามของเราถูกไปวางบน Embedding Space แล้วหาว่าเราใกล้เคียงคำถามใดเป็นคำตอบออกมาครับ
การหาความใกล้เคียง หรือคล้ายคลึงกันบน Embedding Space เป็นอย่างไร ?
โดยปกติเราจะเรียกวิธีหาความคล้ายคลึงกันของแต่ละอย่างว่า Similarities เช่น Products ในห้างที่มีความใกล้เคียงกันก็อาจวัดด้วย Similarity Score ซึ่งมีหลายเทคนิคที่หาความใกล้เคียงครับ
ในบทความนี้ที่เราพูดถึง Vector Embeddings นั้น เราก็จะคำนวณหา Similarity โดยใช้ Metrics ต่าง ๆ เช่น L2 Distance, Cosine Similarity, Inner Product แบบที่เราเรียนเรื่อง Vector ตอนมัธยมเหมือนกันเลยครับ
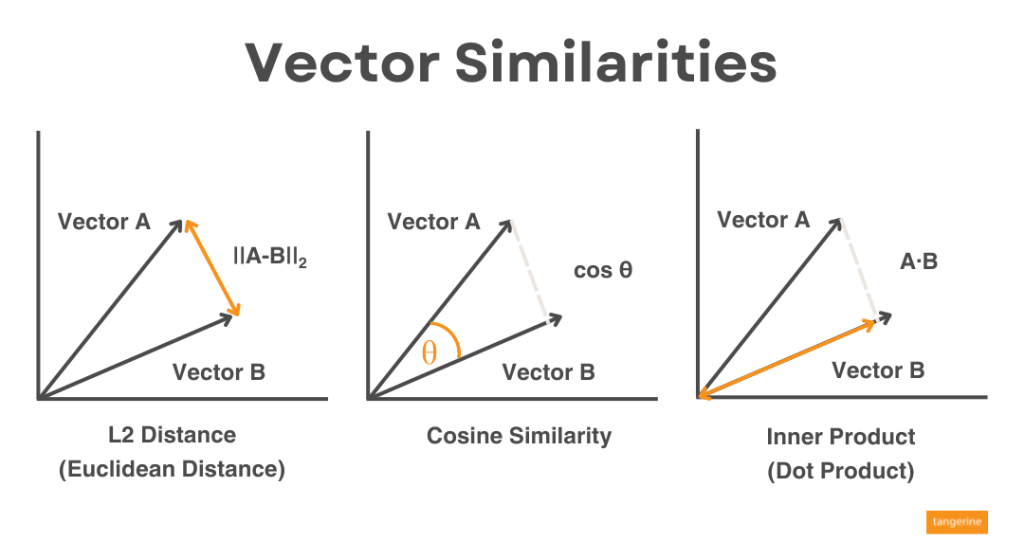
L2 Distance หรือ ระยะทางแบบยุคลิด (Euclidean Distance) เป็นการวัดแบบระยะทางที่มีพื้นฐานจากทฤษฎีพีทาโกรัสครับ เจ้าสามเหลี่ยมที่เราหาความยาวด้านตรงข้ามมุมฉากนี่แหละครับ นำมาหาความใกล้เคียงกัน ยิ่งระยะทางน้อยก็แปลว่ายิ่งใกล้มาก

เคียงกันเท่านั้น โดยปกติ cos(0) = 1, cos(90) = 0 ใช่ไหมครับ ดังนั้นยิ่งมุมน้อย ๆ ก็จะได้เลขใกล้เคียง 1 ยิ่งเหมือนครับ
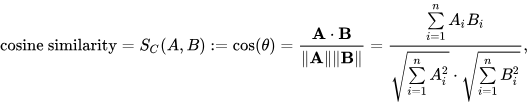
Inner Product หรือ Dot Product เป็นวิธีการคูณของ Vector เหมาะกับ Long Vector ซึ่งมี Vector Length ที่กว้างหรือยาวมาก ทำให้คูณได้ค่าที่มากในแต่ละ Dimension บน Vector ซึ่งในโจทย์นี้ที่เราจะใช้ Google Cloud ด้วย Text Embedding Model ที่มี Dimension ประมาณ 768 Dimensional จะใช้เป็นตัวนี้ครับ
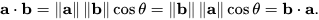
Metrics เหล่านี้เราใช้ในการหาความใกล้เคียงอาจใช้ในการแบ่งกลุ่ม เช่น K-Mean หรือ K-Nearest Negihbors ที่ใช้ L2 Distance และยังมี Metric อื่น ๆ ในโจทย์ Similiarities เช่น Jaccard Similarity, Manhattan Distance, Minkowski Distance และ Chebyshev distance
สำหรับ Google เองก็มี Algorithm เหล่านี้โดยเป็น ANN (Approximate Nearest Neighbor) Algorithm ที่ทรงประสิทธิภาพที่นับไว้เป็น ANN ที่ดีที่สุดในโลกเรียกว่า ScaNN ที่นำมาสร้างเป็น Service Google มากมายอย่าง Google Search, Youtube เป็นต้น และถูกนำมาสร้างเป็น Service บน Google Cloud ที่ชื่อว่า Vector Search
Embeddings API และ Vector Search บน Vertex AI เป็นอย่างไร ?
อย่างที่เกริ่นไว้ในช่วงต้นเรื่อง Vector Search คราวนี้ถึงคิวอธิบายกันแล้ว แต่ถ้าจะให้เข้าใจเห็นภาพกันเลย ผมขอนำไปเขียนเป็นภาคปฏิบัติในบทความถัดไปนะครับ ดังนั้นในหัวข้อนี้จะขออธิบายเป็นเชิงเกริ่นนำของทั้งสองตัวนี้ก่อน
Embeddings API

จริง ๆ การ Embedding เราสามารถใช้ Open Source หรือ Library ต่าง ๆ Embed เป็น Vector ได้ ซึ่งบางครั้ง อาจจะต้องใช้เวลาในการเตรียมข้อมูลหรือ Training Vocabulary ต่าง ๆ เพื่อความง่ายดายรวดเร็วและทรงพลัง เราสามารถใช้ Text Embeddings Model บน Vertex AI ได้ จะเป็นตัว Model ที่ชื่อว่า textembedding-gecko และมีตัวที่รองรับ Multilingual ชื่อว่า textembedding-gecko-multilingual เราสามารถเรียกใช้บน Model Garden ได้เลยครับ
จริง ๆ ก็สามารถ Embeddings ได้ทั้ง ข้อความ รูปภาพ หรือจะใช้ของค่าย Meta ก็ได้ครับ ลักษณะการใช้งานก็แค่ Call APIs จะได้ Vector กลับมาก็จบกระบวนการ เราสามารถใช้ Vector นี้ไปหา Similarity ด้วย Metric ต่าง ๆ ตามที่แนะนำข้างบนด้วยการโค้ดดิ้งครับ
แต่ปัญหาถัดไปคือหลังจากได้ Vector มาแล้ว เราจะหา Similarity ในการคำนวณแต่ละ Vector ทั้งหมดใน Embedding Space ของเรา อาจจะใช้หน่วยประมวลมากถึงขั้นตอนเก็บข้อมูลอยู่บน Memory เพื่อให้ค้นหาได้ไว ไม่งั้นอาจเกิด Latency นานไม่เหมือนตัวอย่างที่เราเล่นตอนต้นบทความ จึงต้องใช้เครื่องมือมาช่วย Match Vector ครับ นั่นคือ Vector Search
Vertex AI Vector Search
ชื่อเดิมคือ Vertex AI Matching Engine ซึ่งเปลี่ยนชื่อมาเป็น Vector Search นั้นทำให้เข้าใจตัว Product ได้ง่ายขึ้น เราสามารถใช้ตัวนี้ในการค้นหาแบบ Semantic ซึ่งใช้เทคนิคของ Vector Similarity-matching ในการทำ Use-cases แนว Search & Recommendation

หากให้อธิบายง่าย ๆ โดยอ้างอิง Demo ของ Google บนเว็บ ai-demos.dev สำหรับ Vector Search เราจะแบ่งเป็นภาพใหญ่ 2 Step ครับ
- Build Index
- Deploy
Build Index
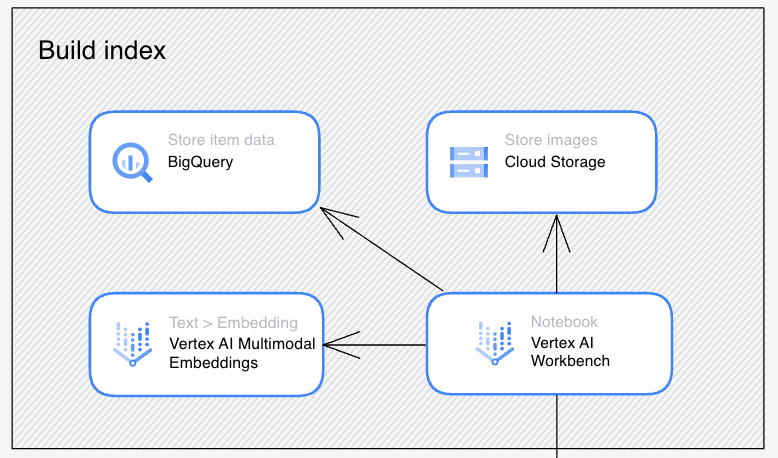
ในการ Build Index เราจะได้นำผลลัพธ์จาก Embeddings ไปเก็บบน Cloud Storage ในรูปแบบ JSON ทั้งนี้ผลลัพธ์จากการ Embeddings อาจจะเขียนเองก็ได้หรือใช้ API สำเร็จรูปอย่าง Vertex AI Embeddings ทั้งแบบข้อความหรือ Multimodal ก็ได้ครับ
ถ้าจากภาพตัวอย่างนี้ Google จะใช้ Vertex AI Workbench เขียน Python บน Jupyter Notebook เรียก Vertex AI Multimodal Embedding แล้ว Dump ผลลัพธ์ออกเป็นไฟล์ JSON ไปวางที่ Cloud Storage ครับ เดี๋ยวขั้นตอนเหล่านี้ผมจะเล่าวิธีการในภาคปฏิบัติครับ
Deploy
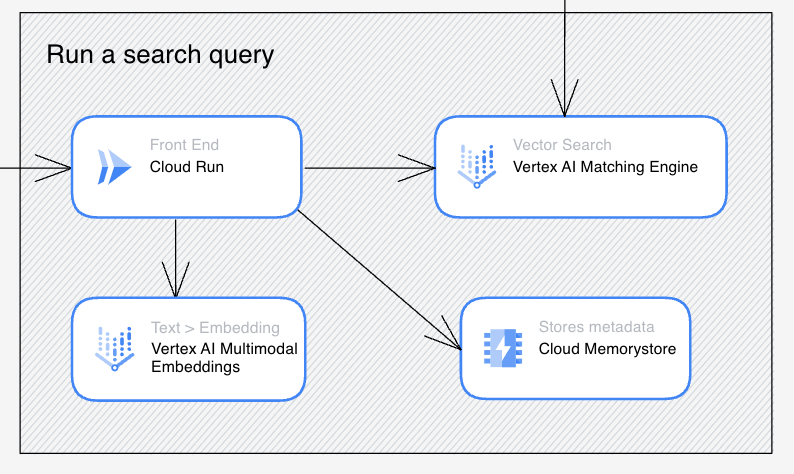
เมื่อได้ Indexing แล้วก็ทำการ Deploy Indexing นี้บนตัว Vector Search ครับ จะได้ออกมาเป็น API Endpoint ไปให้แอปฯ ต่าง ๆ ที่เราเขียนมาเรียกดังภาพข้างต้นที่ใช้ Cloud Run มาเรียกครับ
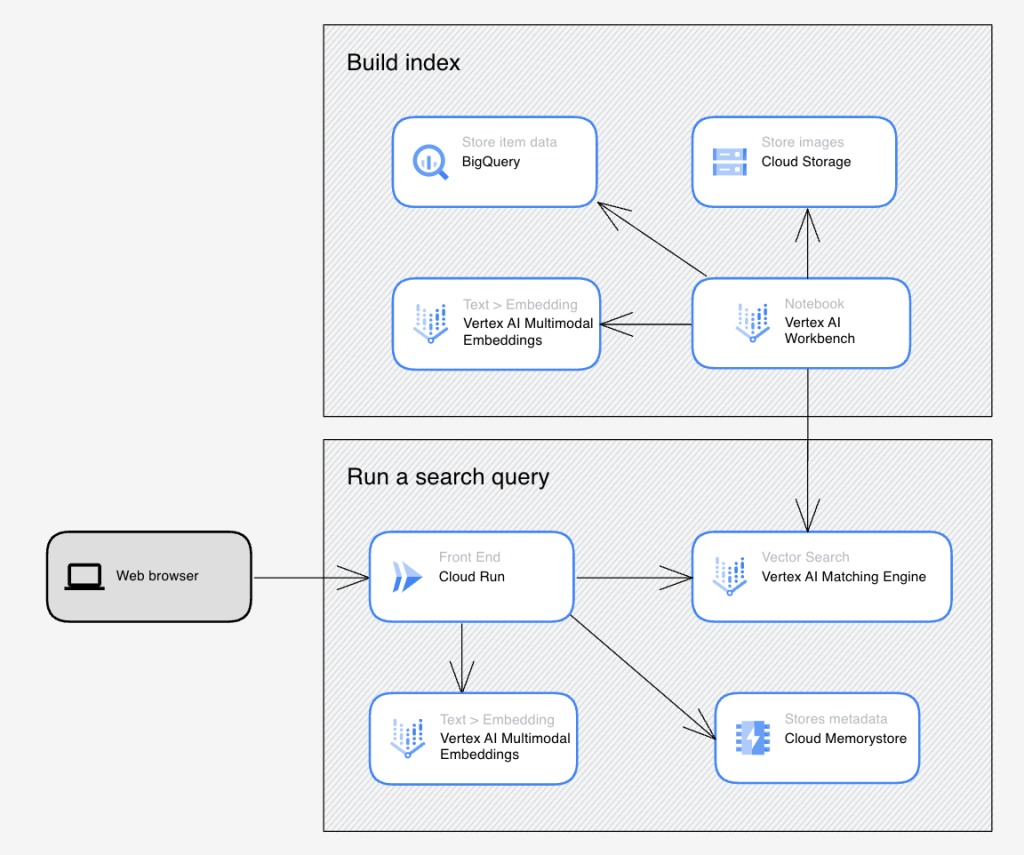
ถ้าจำลองสถานการณ์นี้คือ User มาใช้งานแอปฯ บน Cloud Run โดยมีการ Input Query เข้ามา Query ของ User จะนำไป Embeddings เป็น Vector ในขั้นแรก จากนั้นนำ Vector ที่ได้ไปเข้า Vector Search เพื่อทำการค้นหา Vector ที่ใกล้เคียง และเมื่อรวม 2 ขั้นตอนนั้นเป็นภาพใหญ่เราก็จะได้แอปฯ ที่ทำงานใน Use-cases ต่าง ๆ ได้มากมายดังภาพครับ
Conclusion
ผมหวังว่าผู้อ่านทุกท่านจะได้รู้จักกับ Vector Embedding กันมากขึ้น เพื่อต่อยอดในโลกของ Gen AI ต่อไปครับ ในบทถัดไปภาคปฏิบัติ ผมจะพาทุกท่านไปลองเขียนโค้ด Embeddings + Vector Search กันครับ และทำความรู้จักกับ RAG มากขึ้น เพื่อเข้าใจบริการ Gen AI ที่ดีมาก ๆ บน Google Cloud ตัวหนึ่งนั่นคือ Vertex AI Search & Conversation ครับ แล้วเจอกันในบทความหน้าครับ