
โลกแห่ง AI ก้าวหน้าอย่างรวดเร็ว Deep Learning กลายเป็นเทคโนโลยีหลักที่ขับเคลื่อนนวัตกรรมมากมาย แต่ความฉลาดของ AI เหล่านี้ก็มาพร้อมกับความท้าทายเช่นกัน โดยเฉพาะเมื่อนำไปใช้ในสถานการณ์จริงที่ความผิดพลาดอาจส่งผลกระทบร้ายแรง นั่นจึงเป็นที่มาของ Reliable Deep Learning หรือการพัฒนา Deep Learning ให้มีความน่าเชื่อถือมากขึ้น
Reliable Deep Learning คืออะไร?
ลองนึกภาพระบบ AI เกี่ยวกับ Health Care เช่น วินิจฉัยโรคผิวหนัง หากระบบเจอโรคที่ไม่เคยเรียนรู้มาก่อน มันอาจจะเดาไปว่าเป็นโรคอื่นที่ใกล้เคียง พร้อมกับความมั่นใจเต็มเปี่ยม ซึ่งมันค่อนข้างอันตรายมาก!
ผลการทำนายที่ผิดเหล่านี้เราเรียกว่า “Confidently Wrong” หรือ “ผิดพลาดอย่างมั่นใจ” เพราะบางงานของการทำ Model มันควรผิดพลาดไม่ได้เลยหรือน้อยมากที่สุด ซึ่งหากเราทำเป็น Classification Model ที่อาจทำนายคำตอบนี้อยู่ในหมวดหมู่ Other ก็ได้ แต่ปัญหาจะเกิดขึ้นหาก Training Data ของเราสำหรับหมวดหมู่ Other ไม่มีหรือไม่เพียงพอ
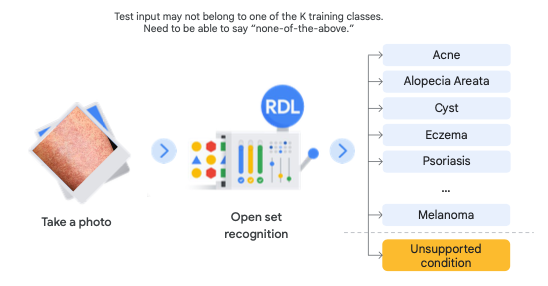
ดังนั้น Reliable Deep Learning จึงเข้ามาแก้ปัญหานี้ โดยมุ่งเน้นพัฒนาโมเดล Deep Learning ให้มีภูมิคุ้มกันกับข้อมูลที่ไม่แน่นอน ซึ่งโมเดลจะให้คะแนนความไม่เชื่อมั่น (Uncertainty Scores) สูง เมื่อต้องทำนายสิ่งที่ไม่เจอใน Training Dataset เช่น เมื่อต้องทำนายโรคผิวหนังที่ไม่เคยพบหรือรู้จักมาก่อน เป็นต้น โดย Reliable Deep Learning ต้องมีคุณสมบัติดังนี้
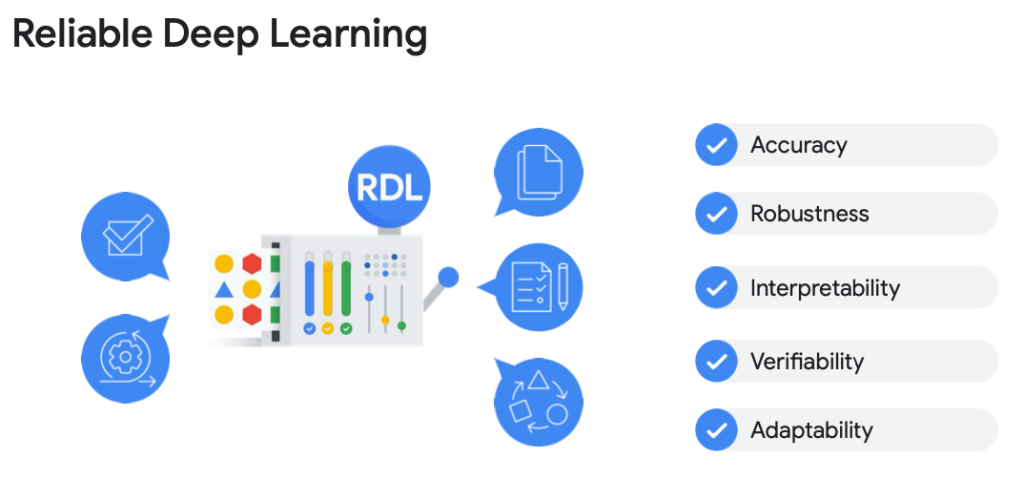
- ความแม่นยำ (Accuracy): ทำนายได้อย่างแม่นยำกับข้อมูลที่หลากหลาย
- ทนทาน (Robustness): ทำงานได้ดีแม้เจอข้อมูลที่ไม่คาดคิดหรือข้อมูลที่พยายามหลอกระบบ
- ตีความได้ (Interpretability): อธิบายการตัดสินใจได้อย่างโปร่งใส สร้างความเข้าใจและน่าเชื่อถือ
- ตรวจสอบได้ (Verifiability): สามารถตรวจสอบ Properties และพฤติกรรมของโมเดลได้
- ปรับตัวได้ (Adaptability): ปรับตัวเข้ากับสภาพแวดล้อมหรือข้อมูลใหม่ๆ ได้
Reliable Deep Learning ต่างจาก Deep Learning ทั่วไปอย่างไร?
Deep Learning ทั่วไปมักให้ความสำคัญกับความแม่นยำเป็นหลัก แต่ Reliable Deep Learning ให้ความสำคัญกับคุณสมบัติทั้งหมดที่กล่าวมาข้างต้นอย่างเท่าเทียมกัน นอกจากนี้ยังใช้วิธีการจากหลายศาสตร์ ทั้งสถิติ ทฤษฎีความน่าจะเป็น เพื่อพัฒนาประสิทธิภาพของโมเดลอย่างละเอียด
ทำไม Reliable Deep Learning ถึงสำคัญ?
เพราะโลกแห่งความจริงซับซ้อนกว่าข้อมูลที่ใช้ฝึก AI ความผิดพลาดของ AI ในบางสถานการณ์ เช่น การแพทย์ การเงิน หรือระบบขับเคลื่อนอัตโนมัติอย่างรถยนต์เองก็ดีหรือท่าอากาศยานไร้คนขับก็ดี อาจส่งผลร้ายแรงได้ Reliable Deep Learning จึงมีความสำคัญในการสร้าง AI ที่น่าเชื่อถือ ปลอดภัย และนำไปใช้ได้จริง
วิธีการสร้าง Reliable Deep Learning
ทุกท่านพอจะเข้าใจ Reliable Deep Learning พอสังเขปกันแล้ว ทีนี้เรามาดูวิธีการสร้าง Reliable Deep Learning กันดีกว่า ซึ่งมีหลายเทคนิคที่ใช้กัน แต่มี 2 วิธีหลักๆ ที่นิยมใช้คือ
1. Ensemble Models
เป็น Train โมเดลหลายๆ ตัวแล้วนำผลลัพธ์มารวมกัน คล้ายกับการขอความเห็นจากผู้เชี่ยวชาญหลายคน วิธีนี้ช่วยเพิ่มความน่าเชื่อถือได้มาก แต่ก็ต้องใช้ทรัพยากรในการคำนวณสูง
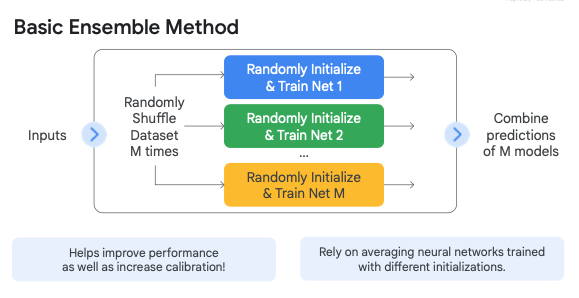
เมื่อใช้ทรัพยากรในการคำนวณสูงจึงมีอีกเทคนิคที่เรียกว่า Batch Ensemble ซึ่งใช้กลไก 2 อย่างคือ
- Shared Weights: ทุก Network Copies จะใช้ Weight (W) เดียวกัน
- Low-rank Perturbations: แต่ละ Network Copies จะถูกปรับเปลี่ยนโดยใช้ Low-rank perturbations ที่ไม่ซ้ำกันกับ Shared weight ทำได้โดยเอา W คูณกับ Low-rank matrix (F) ซึ่งแทนด้วย Wi = W (dot) F
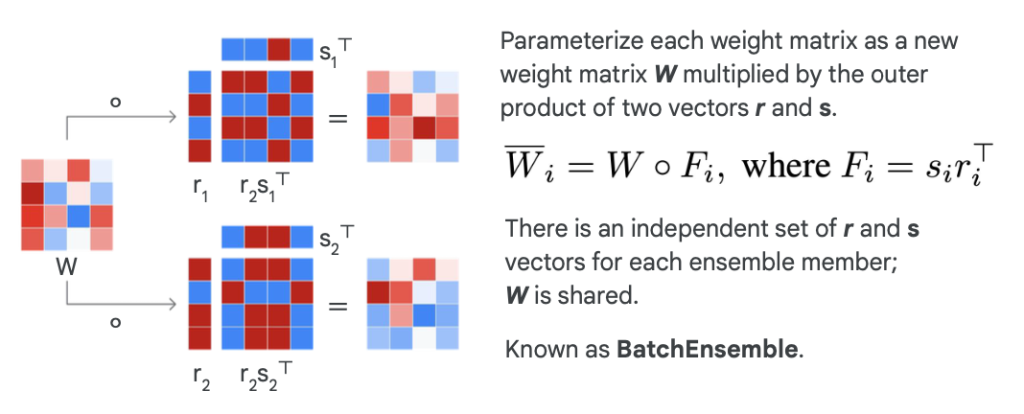
วิธีการนี้จะช่วยลดจำนวนพารามิเตอร์ที่ต้องเรียนรู้และเก็บไว้ได้อย่างมาก ทำให้มีประสิทธิภาพในการคำนวณมากกว่าการแยก Train Model แต่ละตัวใน Ensemble Model
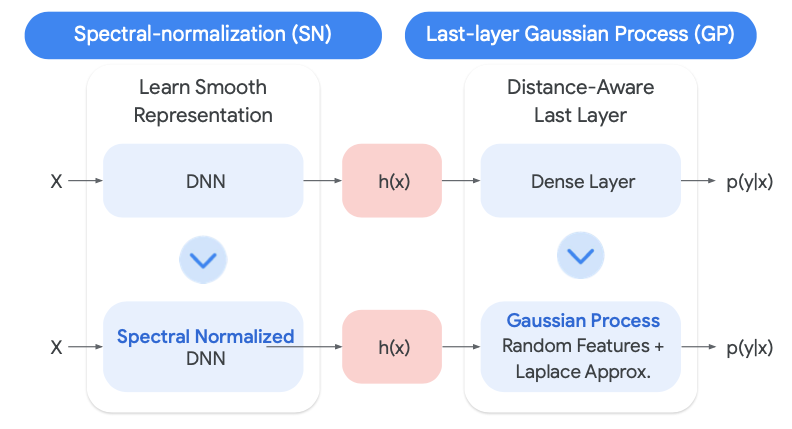
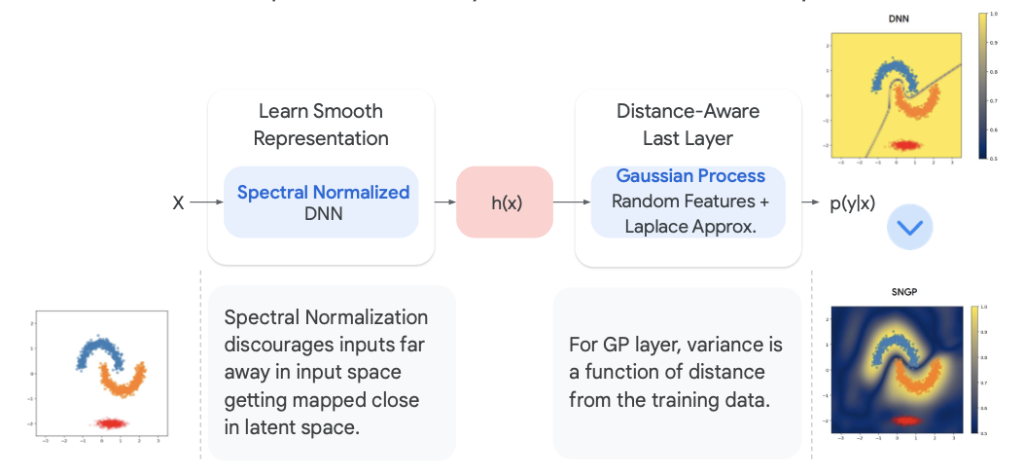
2. Spectral-Normalized Neural Gaussian Process (SNGP)
เทคนิคที่พัฒนาโดย Google เป็นวิธีที่ช่วยเพิ่มความน่าเชื่อถือได้โดยไม่ต้องฝึกโมเดลหลายตัว
SNGP จะปรับเปลี่ยนวิธีการทำโมเดลเล็กน้อย ทำให้โมเดลสามารถประเมินความไม่แน่นอนของตัวเองได้ดีขึ้น เมื่อเจอข้อมูลที่ไม่คุ้นเคย โมเดลจะแสดงความไม่มั่นใจ (Uncertainty Score) ออกมา แทนที่จะเดาไปอย่างมั่นใจแบบผิดๆ
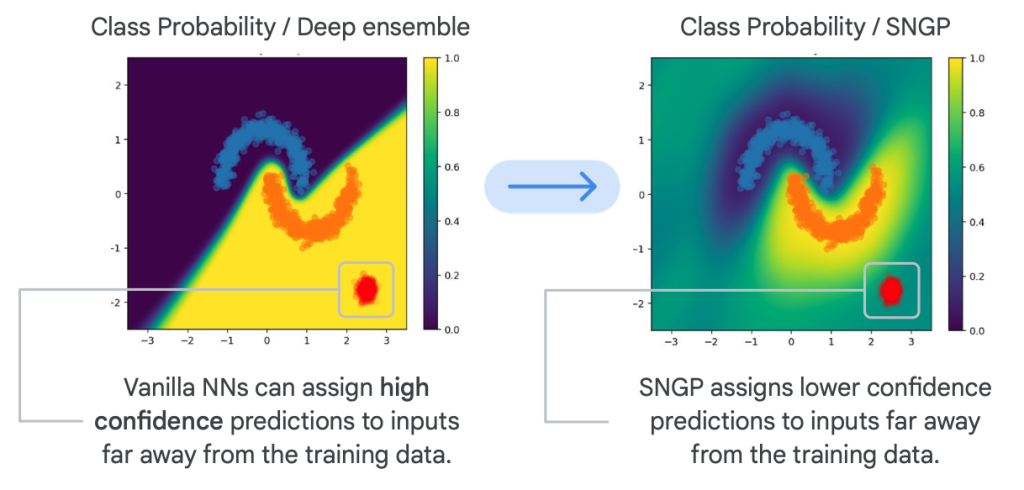
เพื่อความเข้าใจมากขึ้นตามภาพประกอบนี้ หากไม่มี SNGP (ภาพซ้าย) โมเดลอาจทำนายข้อมูลที่ป้อนเข้าไป (จุดสีแดง) ว่าคือผลลัพธ์คงอยู่ใน Class โซนสีเหลืองของ Vanilla NNs แต่ถ้ามี SNGP (ภาพขวา) จะทราบว่าข้อมูลสีแดงที่ป้อนเข้าไปนั้นอยู่ห่างจาก training data มาก แสดงผลลัพธ์ทำนายที่ไม่มั่นใจออกมา เพราะ SNGP มีการใช้ “ระยะทาง-ตระหนัก” (Distance-Aware) ให้เห็นถึงความห่างจากข้อมูลที่ใช้ Train เพื่อไม่ให้เกิด Confidently Wrong
ทำไม Vanilla DNNs ถึงให้ค่า Confidence Prediction สูงขณะที่อยู่ไกลจาก Training Data มาก?
Deep Neural Networks (DNNs) แบบ Vanilla หรือแบบมาตรฐานนั้นเก่งกาจในการเรียนรู้จากข้อมูล แต่จุดอ่อนคือ Confidence Prediction หรือความมั่นใจในการทำนายสูงเกินจริง
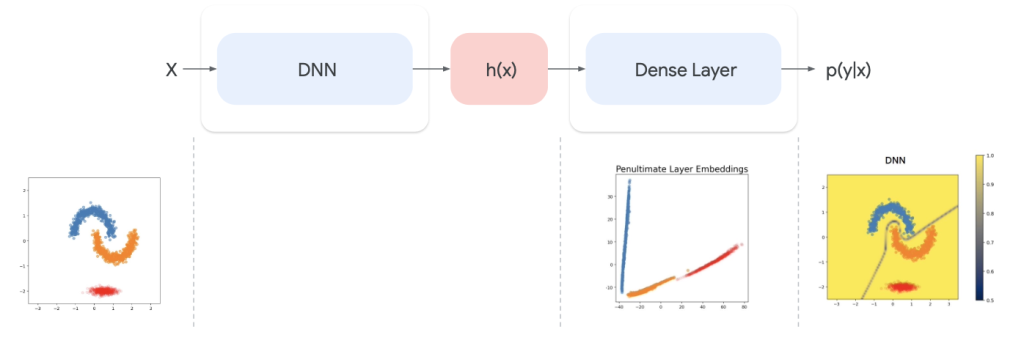
ลองนึกภาพข้อมูลที่กระจัดกระจายอยู่ในมิติที่สูงและซับซ้อนมากๆ DNNs จะเรียนรู้ที่จะบีบอัดข้อมูลเหล่านี้ลงในมิติที่ต่ำลง ซึ่งเรียกว่า Embedding Space หรือ Latent Space
การบีบอัดนี้คล้ายการฉายภาพสามมิติลงบนพื้นผิวสองมิติ สิ่งที่เกิดขึ้นคือข้อมูลที่อยู่ไกลกันในมิติเดิม อาจถูกฉายลงมาอยู่ใกล้กันในมิติใหม่ ปัญหาก็คือ หากข้อมูลที่ต่างกันมากๆๆ ในโลกความจริง พอถูกบีบอัดให้อยู่ใกล้กันใน Embedding Space โมเดลจะแยกแยะข้อมูลเหล่านั้นได้ยากขึ้น เพราะสิ่งที่ไกลพอบีบอัดแล้วมันใกล้เหลือเกิน นำไปสู่การทำนายที่ผิดพลาด และที่แย่กว่านั้นคือโมเดลยังมั่นใจในการทำนายที่ผิดพลาดนั้นอีกด้วย
อีกเรื่องคือการใช้ Softmax Layer เพื่อแปลงคำทำนายให้ลงตาม Class มันก็มักจะให้ความน่าจะเป็นที่สูงกับ Class ใด Class หนึ่งเกินไปแบบมั่นใจมากๆ แม้ว่าข้อมูลจะอยู่ไกลจาก Training Data โมเดลก็ตอบอย่างมั่นใจแม้ว่าจะไม่รู้จักข้อมูลนั้นๆ ดีพอเลย
จึงเป็นที่มาของการใช้ SNGP โดยใช้ Spectral Normalized เพื่อให้ข้อมูลที่บีบอัดลง Embedding Space ไม่ใกล้กันเกินไป เปรียบเสมือนรักษาระยะห่างระหว่างข้อมูลที่มิติลดลง ร่วมกับการแทน Softmax Layer ด้วย Gaussian Process Layer เพื่อพิจารณาระยะห่างระหว่างข้อมูลที่ป้อนกับข้อมูลที่เคยเรียนรู้ หากข้อมูลที่ป้อนเข้าไปอยู่ไกลจากข้อมูลที่เคยเรียนรู้ ค่าความไม่แน่นอน (Uncertainty Scores) จะสูงขึ้น แสดงถึงความไม่มั่นใจของการทำนายสิ่งที่เราต้องการ
ซึ่งทุกท่านหากอยากลองใช้เทคนิค SNGP ก็สามารถอ่านเพิ่มเติมและปรับใช้ตามโค้ดตัวอย่างได้ที่เว็บ Tensorflow ครับ
Conclusion
Reliable Deep Learning คือ ก้าวสำคัญในการพัฒนา AI ให้มีความน่าเชื่อถือ โดยมุ่งเน้นที่ความแม่นยำ ความทนทาน ความสามารถในการตีความ ตรวจสอบ และปรับตัว เทคนิคต่างๆ เช่น Ensemble Models และ SNGP ช่วยให้เราสร้าง AI ที่ปลอดภัยและนำไปใช้ได้จริงในสถานการณ์ที่ความผิดพลาดอาจส่งผลกระทบร้ายแรงในอนาคต ดังนั้น Reliable Deep Learning จะมีบทบาทสำคัญในการสร้าง AI ที่เป็นประโยชน์และ น่าเชื่อถือสำหรับทุกคนครับ

