
สวัสดีเหล่านักพัฒนาและผู้หลงใหลใน Gen AI! เคยสงสัยไหมว่า ทำไมการประมวลผลด้านภาษาถึงมีค่าใช้จ่าย แล้วตัวอักษรภาษาไทยกับภาษาอังกฤษ นับแบบไหน คิดเงินอย่างไร ?
บทความนี้จะพาคุณไปไขความลับของ การนับตัวอักษร และ ค่าใช้จ่ายของ Gemini แบบเจาะลึกบน Vertex AI และ AI Studio ไปพร้อม ๆ กันครับ
เข้าใจ Input และ Output จาก Gemini กันก่อน

โดยปกติเวลาเราเรียกใช้ Gemini Model บน Vertex AI เรามักใช้ผ่าน Vertex AI Studio กันใช่ไหมครับ สิ่งที่เราพิมพ์ถาม Gemini นั่นคือ Input และคำตอบก็คือ Output ครับ จากตัวอย่างข้างต้นก็เป็นข้อมูลในรูปแบบ Text เราเรียกว่า Text Input และ Text Output ครับ ซึ่งสามารถลองทดสอบได้บน Vertex AI Studio
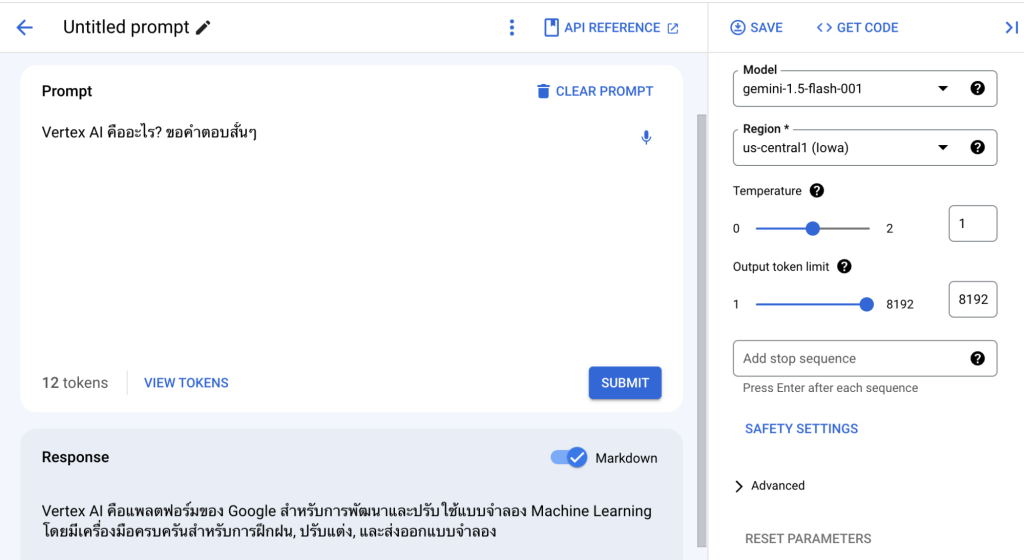
แต่หากเป็น Data Type อื่นก็อาจจะอยู่รูปแบบของ Image, Video และ Audio ซึ่งบน Gemini ก็จะมี Rate คิดเงินที่แตกต่างกันไป ถ้าเป็น Text ก็คิดตามจำนวนตัวอักษร ถ้าเป็นรูปภาพก็คิดตามจำนวนรูป (ไฟล์ PDF คิดเป็นอัตราเดียวกับรูปภาพ 1 หน้า = 1 รูป) หรือวิดีโอก็คิดเป็นวินาที
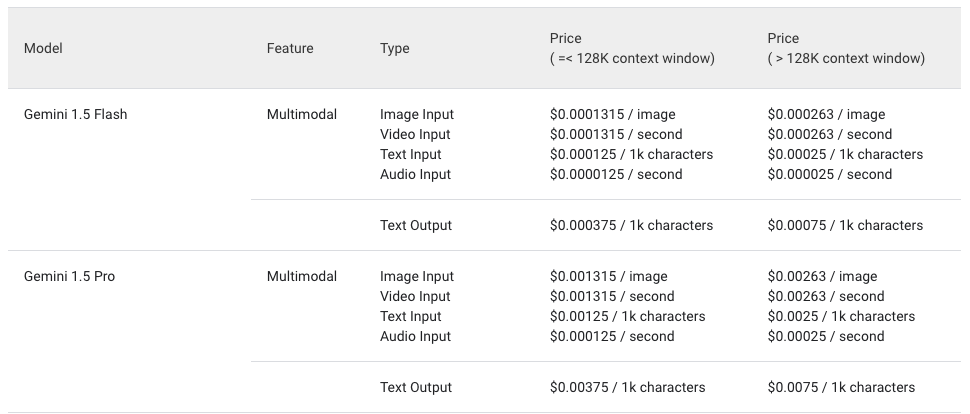
Generative AI on Vertex AI Pricing
Input ที่เราใช้กันบ่อยมักจะเป็น Text โดยมีข้อสังเกตนิดนึงว่า หากเราใช้ Gemini บน Vertex AI จะมีราคาตามตารางข้างต้นที่คิดเป็นตัวอักษร แต่ถ้าเราใช้ Gemini บน AI Studio เช่น ขอ API Key มาใส่บน App ของเรา จะคิดราคา Text Input/Output ตาม Token ซึ่ง 1 Token ก็คือประมาณ 4-5 ตัวอักษรแล้วแต่การตัด Token ด้วยครับ ราคาจะเป็นดังตารางต่อไปนี้
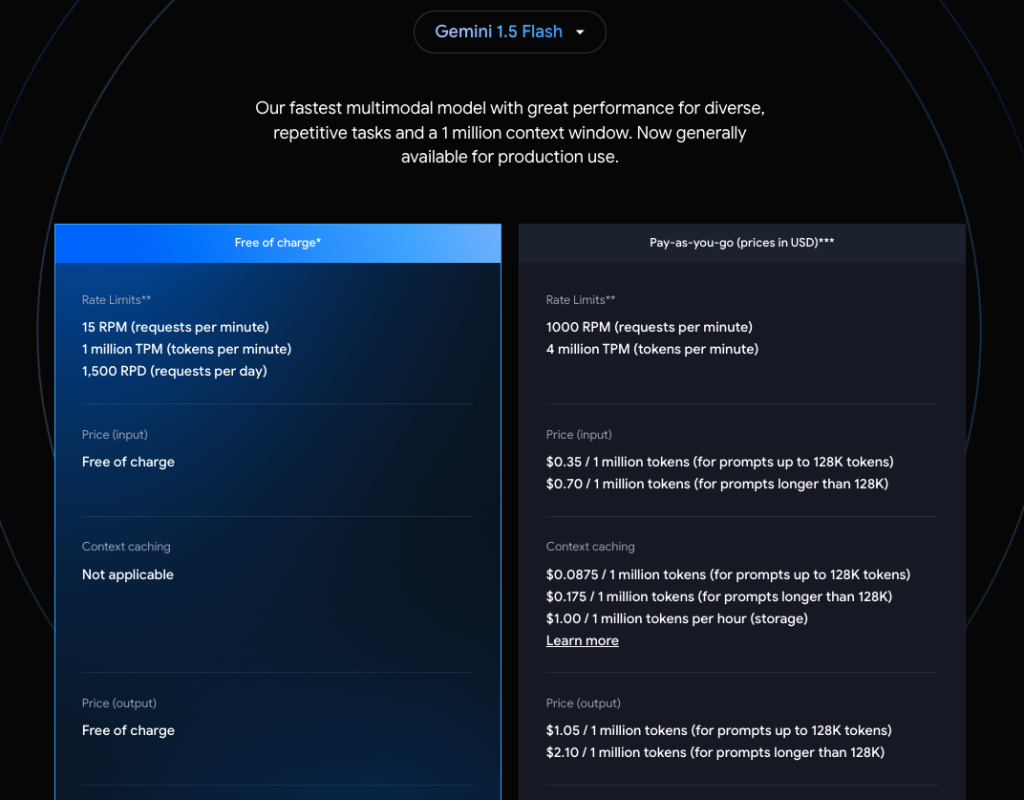
Gemini on Google AI for Developers
ดังนั้นทำให้การคิดราคาตาม Token อาจจะค่อนข้างยากนิดนึง ซึ่งเราก็จะคิดเป็นเลขกลม ๆ แทนอาจจะคิดได้ได้ง่ายเป๊ะ ๆ ตามตัวอักษรแบบ Gemini บน Vertex AI ครับ หลายคนอาจคิดว่าเราสามารถเรียก Gemini ได้ทั้ง 2 แบบซึ่งแล้วแต่ว่ามันแตกต่างกันไหม คำตอบคือไม่แตกต่างครับ แต่บน AI Studio จะมีโมเดลให้เลือกจำกัด เช่น Gemini, Gemma ขณะที่บน Vertex AI มีให้เลือกค่อนข้างเยอะเลยครับ เช่น Gemini, PaLM, Codey หรืออื่น ๆ ครับ
เราจะคำนวณ Token ที่ใช้ได้อย่างไร ?
หลายคนคงมีคำถามประมาณนี้ในหัว เพราะทราบแล้วว่าการนับตัวอักษรง่ายกว่านับ Token ซึ่งมันอยู่ที่ Tokenization Algorithms ด้วย แต่บน Google ที่เราทดสอบ Prompt ก็จะมีตัวนับอยู่แล้วครับ
Vertex AI Studio
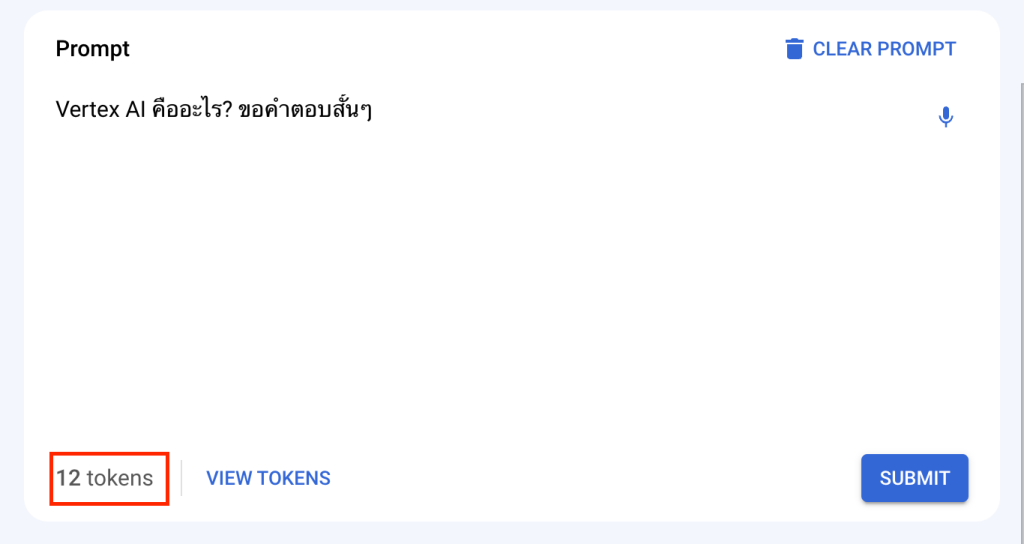
Google AI Studio
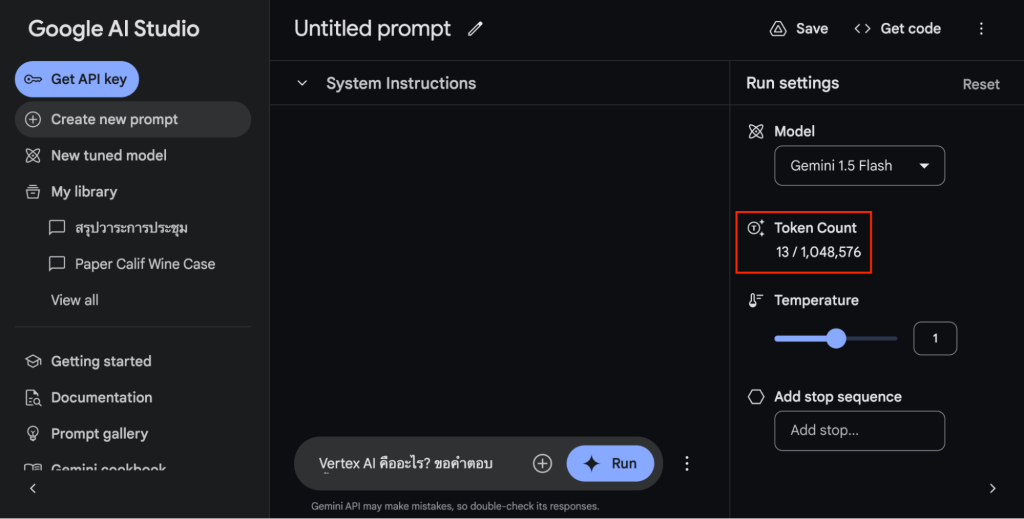
สมมติ Prompt ของผู้เขียนคือ “Vertex AI คืออะไร ? ขอคำตอบสั้น ๆ” ถ้าเราเป็นตัวอักษรจะได้แบบรวมช่องว่าง (Space) ด้วยจะได้ 31 Characters แต่หากนับแบบไม่รวมช่องว่างซึ่งบน Vertex AI จะนับแต่ตัวอักษรไม่รวมช่องว่างครับได้เท่ากับ 28 Characters แต่เมื่อใช้ Tokenizer แล้วจะได้เท่ากับ 12 Token ครับ แบ่งดังนี้ Vertex AI คืออะไร? ขอคำตอบสั้น ๆ
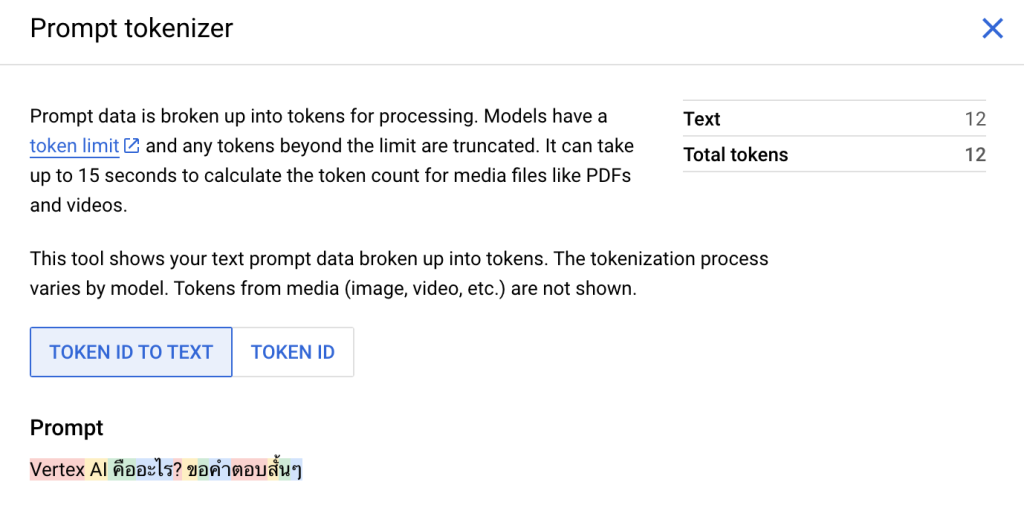
ประเด็นคือเราบอกว่า 1 Token ประมาณ 4-5 Characters มักใช้กับภาษาอังกฤษ แต่ภาษาไทยนั้นใช้ Bytes ในตัวอักษรเยอะกว่า ถ้าเราเอา 28 ตัวอักษร หารด้วย 5 เลยจะได้ 6 Tokens ซึ่งไม่ตรงกับ Tokenizer ข้างต้นเลย มันจะดูน้อยกว่าปกติ
ดังนั้นหากลองคำนวณแบบภาษาไทยแบบ Roughly ที่ใช้ Bytes มากกว่าอังกฤษ 2 เท่า ก็น่าจะเอา 28×2 แล้วหาร 5 ดู จะได้ประมาณ 11.2 ปัดขึ้นเป็น 12 Token ก็พอใช้ได้ครับ แต่ในความเป็นจริงที่ตัวอักษรเยอะ ๆ ก็ไม่ควรหารแบบนี้ตรง ๆ ตัวเลขอาจคลาดเคลื่อนได้ เราควรใช้ Prompt tokenizer มากกว่า และการคิดเป็นตัวอักษรก็ค่อนข้างง่ายกว่ามาก ๆ แถม Gemini ก็ราคาถูกที่สุดด้วย เดี๋ยวจะมาคำนวณให้ดูใน Blog ถัดไปนะครับ แต่ก่อนจะไปเทียบกับค่ายอื่น เรามาเข้าใจอีกนิดนึงว่าการคิดแบบ Token กับแบบ Character บน Gemini ราคาต่างกันไหมอย่างไรดีกว่าครับ
การคิดเงินแบบ Tokens vs Characters
สมมติเรามี Input Prompt (12 Token, 28 Characters without space)
| Vertex AI คืออะไร? ขอคำตอบสั้น ๆ |
และ Output Prompt (39 Token, 118 Characters without space)
| Vertex AI เป็นแพลตฟอร์ม AI จาก Google ที่ให้บริการเครื่องมือและทรัพยากรที่ครบวงจรสำหรับการพัฒนาและใช้งานโมเดล Machine Learning |
ลองคำนวณแบบจำนวนตัวอักษรของ Gemini 1.5 Flash on Vertex AI
- Text Input $0.000125 / 1k characters
- Text Output : $0.000375 / 1k characters
Input Cost = 28 Characters / 1000 x $0.000125 = $0.0000035
Output Cost = 118 Characters / 1000 x $0.000375 = $0.00004425
Total Cost = $0.00004775 ประมาณ 0.0017 Thai Baht
ลองคำนวณแบบจำนวนตัวอักษรของ Gemini 1.5 Flash on Google AI Studio
- Text Input $0.35 / 1 million tokens
- Text Output : $1.05 / 1 million tokens
Input Cost = 12 Tokens / 1,000,000 x $0.35 = $0.0000042
Output Cost = 39 Tokens / 1,000,000 x $1.05 = $0.00004095
Total Cost = $0.00004515 ประมาณ 0.0016 Thai Baht
ซึ่งเมื่อคิดเป็นราคาต่างกันประมาณ 0.0001 บาท คือแทบไม่แตกต่างกันเลยเมื่อ On Productions ใช้งานจริง ดังนั้นจึงไม่ต้องกังวลว่าเราจะเลือกใช้ Gemini บน Platform ไหนครับ
ตัวอักษรไทยคิดเงินยังไงบน Gemini ?
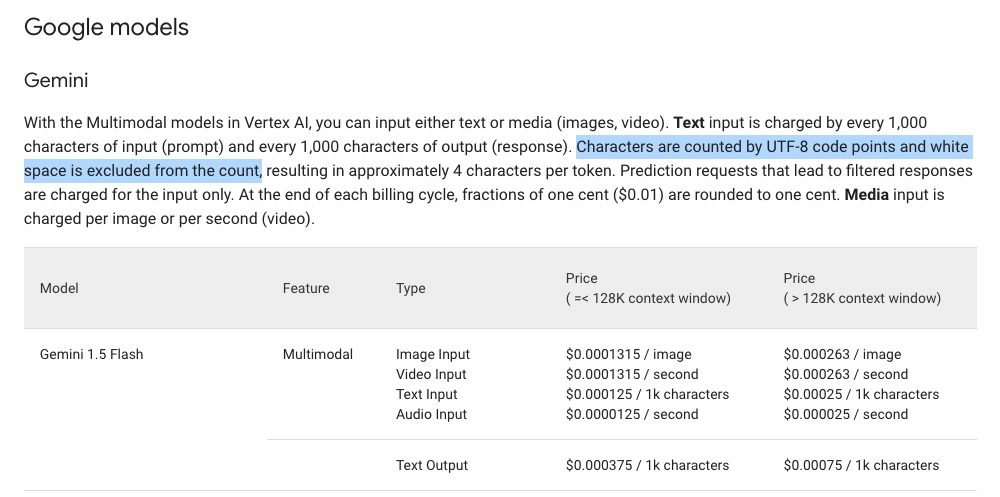
จากเอกสารของทาง Google การคิดตาม Characters จะถูกนับแบบ UTF-8 Code Points นับแต่ตัวอักษรโดยไม่รวมช่องว่าง ซึ่งตามหลัก Unicode แล้ว 1 Character ภาษาไทยใช้ 1 Code Points ครับ ก็สามารถนับเป็น 1 ตัว ต่อ 1 Characters ได้เลย บางท่านอาจคิดว่าภาษาไทยใช้ Bytes เยอะกว่าอังกฤษเลยต้องคิดดับเบิ้ลหรือเปล่า หรือว่าเหมือนในยุค SMS ที่เวลาเราส่ง SMS ภาษาไทยจะส่งได้น้อยลงครึ่งนึง ก็อาจจะสงสัยตรงนี้เพิ่มเติม เดี๋ยวผมจะมาเล่าให้ฟังอย่างกระจ่างครับ
การนับ Character มีกี่แบบ ? นับกันยังไง ?
การนับตัวอักษรไม่ใช่แค่การนับว่ามีกี่ตัว แต่ละวิธีมีหลักการและผลลัพธ์ที่ต่างกัน ไปดูกันครับว่ามีวิธีไหนบ้าง :
- นับแบบ Bytes : เป็นการนับเลยว่าตัวอักษรนี้ใช้กี่ไบต์ในหน่วยความจำ ตัวอักษรภาษาอังกฤษตัวละ 1 Bytes ส่วนภาษาไทยอาจมากกว่าเป็น 2-3 Bytes
- นับแบบ Code Units : วิธีนี้คำนึงถึงชุดค่า Bit ที่รวมกันแล้วเล็กที่สุดในการแสดงตัวอักษร 1 ตัว ซึ่งหมายความว่า 1 Code Unit อาจจะใช้ 1 ไบต์ ของ UTF-8 หรือ 2 ไบต์ ใน UTF-16 ก็ได้
- นับแบบ Code Points : วิธีนี้แม่นยำที่สุดนับตัวอักษรตามค่า Unicode ที่เป็น integer บนช่วง U+0000 ถึง U+10FFFF โดยภาษาไทยเริ่มที่ U+0E01 (ก.ไก่) จบที่ U+0E5B (๛โคมูตร)
- นับแบบ Grapheme Clusters : วิธีนี้มองตัวอักษรแบบรวมกลุ่ม เช่น Emoji ยิ้ม 😃 นับเป็น 1 Grapheme Cluster แม้ว่าบาง Emoji อย่างน้องที่ถอนหายใจ 😮💨 จะใช้หลาย Code Points มากกว่า 1 ก็ตาม ในส่วนนี้เดี๋ยวผมอธิบายเมื่อเราเข้าใจ Code Points มากขึ้นครับ
เจาะลึก Code Point ภาษาไทย
เมื่อเราเข้าใจว่าการนับพวกตัวอักษรมีกี่แบบข้างต้นแล้ว เราก็จะมาโฟกัสกับแบบที่นิยมที่สุดก็คือ Code Points ครับ ขออนุญาตเกริ่นก่อนคือหากเราเป็นสายที่ต้องทำ Data แล้ว เรายุ่งอยู่กับข้อมูลสิ่งสำคัญที่ต้องรู้จักคือ Unicode เป็นเหมือนมาตรฐานในการเข้ารหัสพวกตัวอักษรต่าง ๆ ไม่ว่าภาษาใดในโลกเลย
จริง ๆ อาจต้องเกริ่นถึง ASCII ก่อน แต่หากเล่าเรื่อง ASCII อาจยาวเกิน Gemini ไป งั้นผมขอสรุปประมาณว่าการเข้ารหัสแบบ ASCII เนี่ย มันใช้เนื้อที่อักขระละ 7 bits คำนวณแบบฐาน 2 แล้วได้ 128 แบบหรือ 128 ตัวอักษร แน่นอนว่าเก็บภาษาอังกฤษเนี่ยอาจจะเพียงพ แต่บนโลกไม่ได้มีแค่ภาษาอังกฤษน่ะสิ ก็เลยไม่พอแล้วจึงทำให้เกิดมาตรฐานแบบ Unicode ครับ
ทีนี้มาที่เจ้า Unicode กันบ้าง อักขระแต่ละตัวใน Unicode จะมีเหมือนเลขประจำตัวว่าตัวที่เท่าไร แสดงในฐานสิบหก (Hex) ตั้งแต่ U+0000 ถึง U+10FFFF ก็คือใหญ่จัดรองรับทุกอักขระที่มีมาบนโลกแล้ว
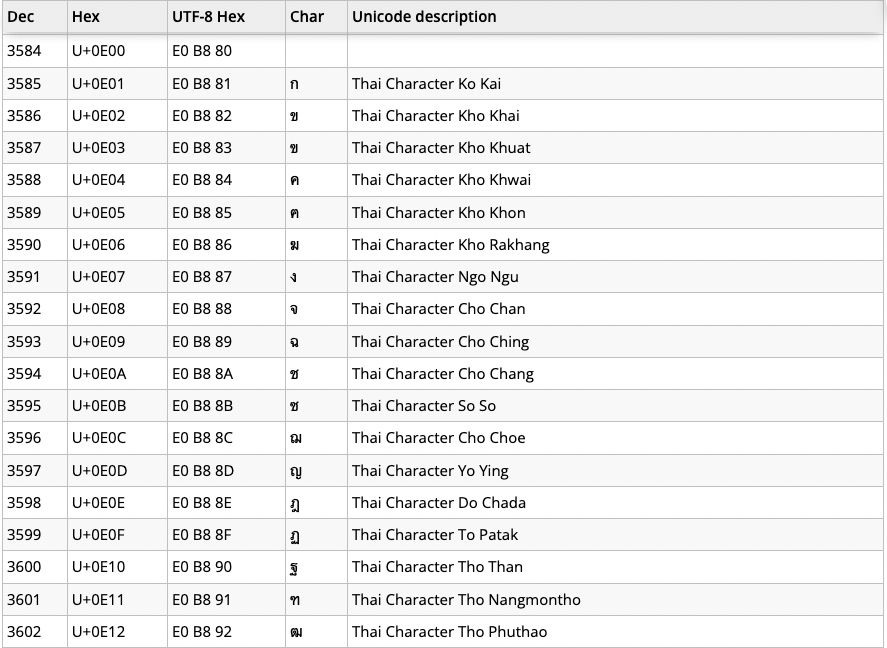
โดยบล็อกภาษาไทยจะเริ่มที่ U+0E01 (ก.ไก่) ถึงตัว U+0E5B (๛โคมูตร) แต่จริง ๆ แล้วภาษาไทยถูกจองไว้ตั้งแต่ U+0E00 ถึง U+0E7F อ้างอิงตาม Wikipedia
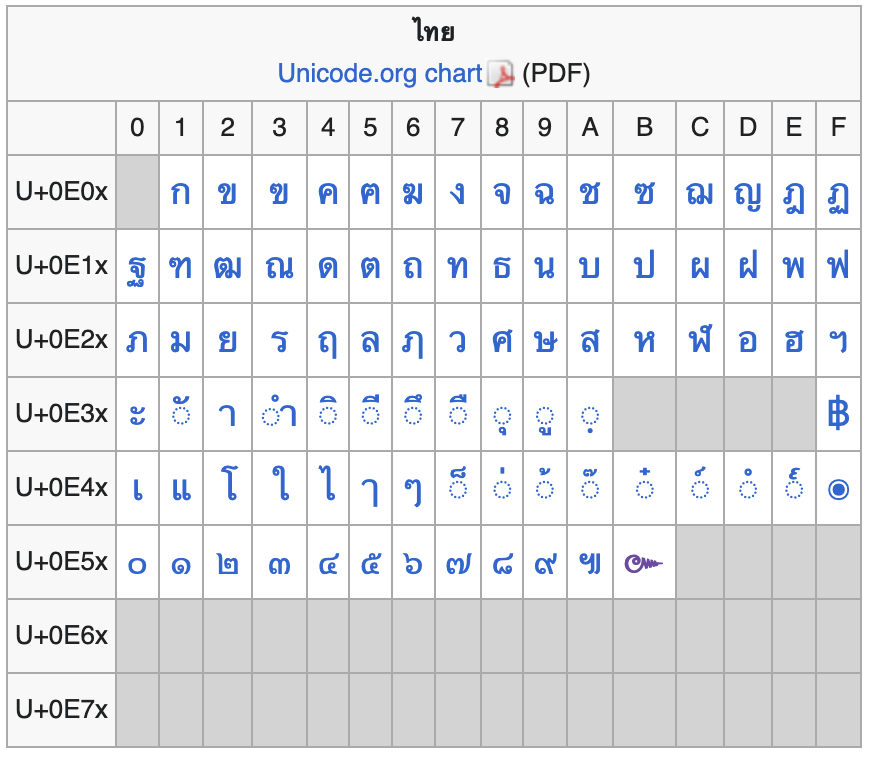
จากตารางข้างต้นแปลว่าภาษาไทยยังมีพื้นที่ให้เล่นอีกเยอะเลยใช่ไหมครับ เผื่อเราจะสร้างอักขระขึ้นมาใหม่
เพื่อให้เข้าใจมากขึ้นผมขอเขียน Python ชุดนึงขึ้นมาวิเคราะห์ตัวอักษรใน Coding ต่าง ๆ กันดังนี้ครับ
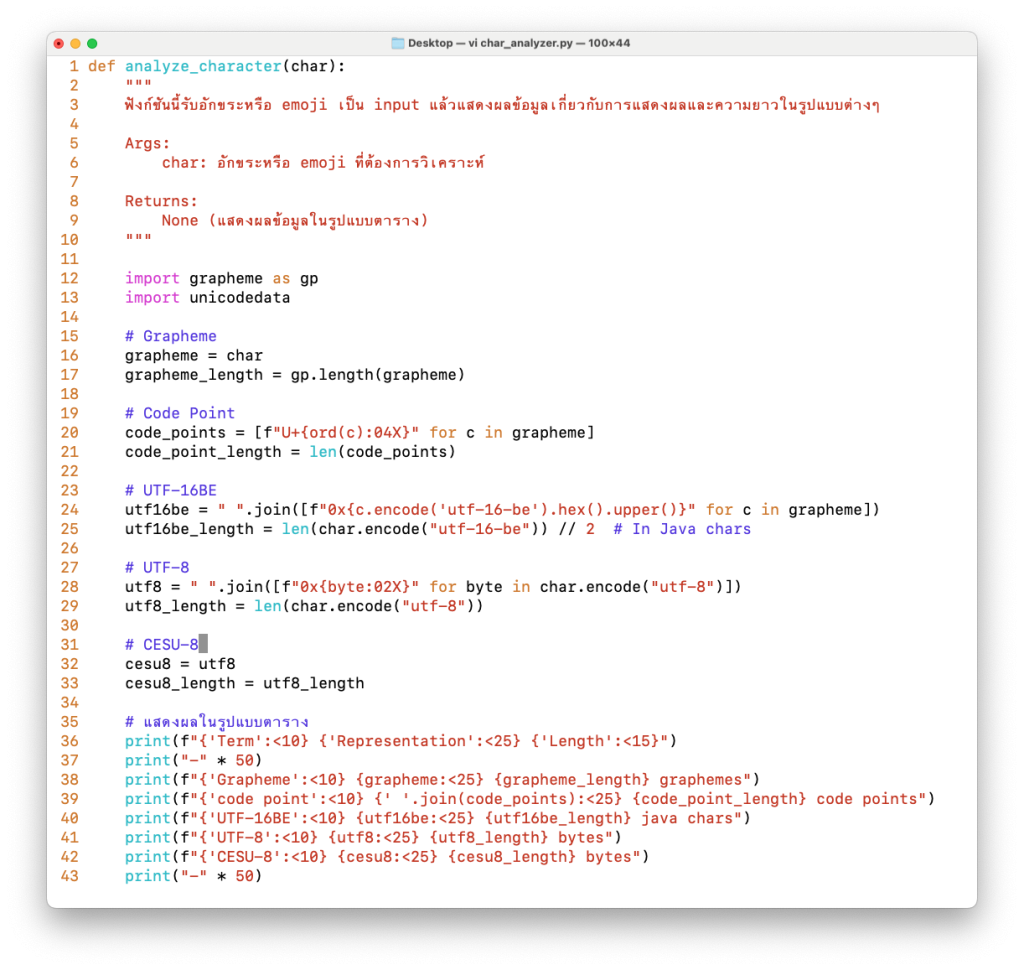
char_analyzer.py
อย่าลืม pip install grapheme ก่อนนะครับ เพราะเราต้องใช้ Lib พิเศษในการนับเจ้า Grapheme เช่นพวก Emoji มันนับโดยพวกฟังก์ชัน Len แบบนี้ไม่ได้แล้ว
def analyze_character(char) :
"""
ฟังก์ชันนี้รับอักขระหรือ emoji เป็น input แล้วแสดงผลข้อมูลเกี่ยวกับการแสดงผลและความยาวในรูปแบบต่าง ๆ
Args :
Char : อักขระหรือ emoji ที่ต้องการวิเคราะห์
Returns :
None (แสดงผลข้อมูลในรูปแบบตาราง)
"""
import grapheme as gp
import unicodedata
# Grapheme
grapheme = char
grapheme_length = gp.length(grapheme)
# Code Point
code_points = [f"U+{ord(c):04X}" for c in grapheme]
code_point_length = len(code_points)
# UTF-16BE
utf16be = " ".join([f"0x{c.encode('utf-16-be').hex().upper()}" for c in grapheme])
utf16be_length = len(char.encode("utf-16-be")) // 2 # In Java chars
# UTF-8
utf8 = " ".join([f"0x{byte:02X}" for byte in char.encode("utf-8")])
utf8_length = len(char.encode("utf-8"))
# CESU-8
cesu8 = utf8
cesu8_length = utf8_length
# แสดงผลในรูปแบบตาราง
print(f"{'Term':<10} {'Representation':<25} {'Length':<15}")
print("-" * 50)
print(f"{'Grapheme':<10} {grapheme:<25} {grapheme_length} graphemes")
print(f"{'code point':<10} {' '.join(code_points):<25} {code_point_length} code points")
print(f"{'UTF-16BE':<10} {utf16be:<25} {utf16be_length} java chars")
print(f"{'UTF-8':<10} {utf8:<25} {utf8_length} bytes")
print(f"{'CESU-8':<10} {cesu8:<25} {cesu8_length} bytes")
print("-" * 50)
while True:
char_input = input("Input Char: ")
analyze_character(char_input)ลอง Save แล้ว Run ดูครับ ซึ่งผมจะลองทดสอบกับตัวอักษร “ก” จะได้ผลดังภาพว่าใช้ 1 Code Points และขนาดประมาณ 3 Bytes
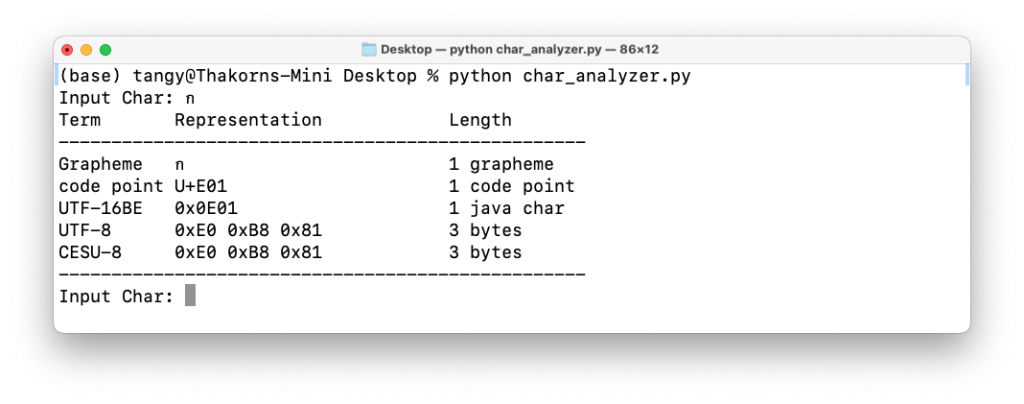
ลอง Emoji 😃 ยิ้มตัวนี้กันบ้างครับ ตัวนี้ใช้ 1 Code Point ขนาด 4 Bytes แต่ก็ยังนับเป็น 1 Grapheme อยู่
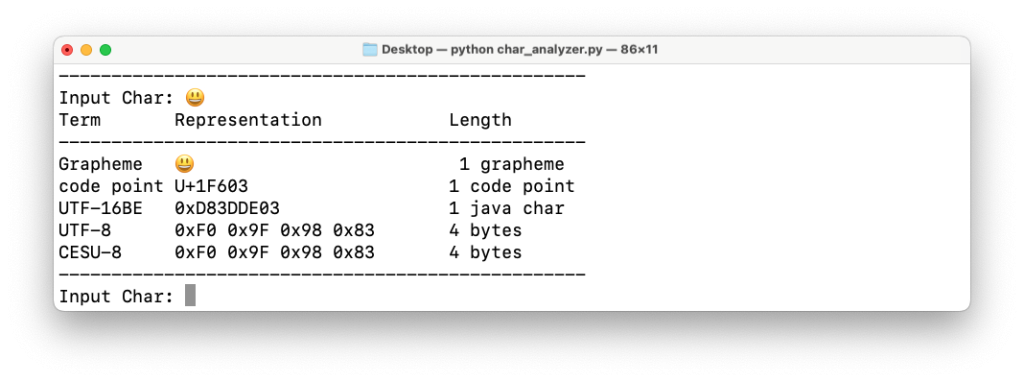
ลอง Emoji 😮💨 ถอนหายใจกันบ้าง ผลลัพธ์จะเห็นว่าใช้ 1 Grapheme และ 3 Code Points ครับ คือจะได้ Emoji ตัวนี้มันประกอบตัว Unicode หลายตัว
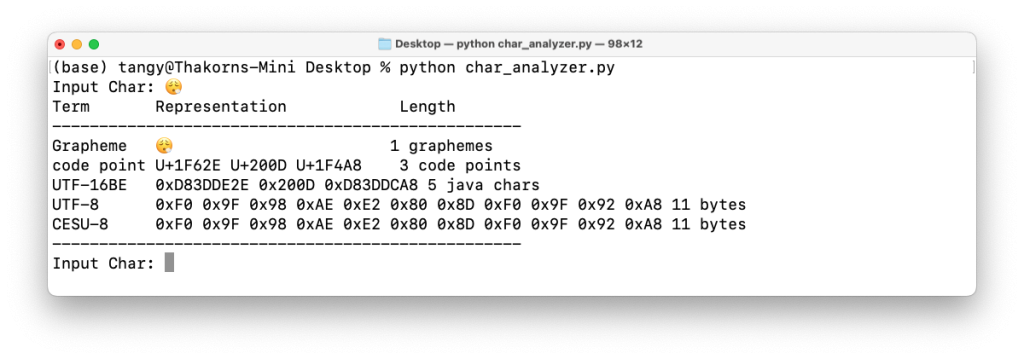
ซึ่งผมลองตัด Unicode ที่ 2 และ 3 ออก (U+1F62E U+200D U+1F4A8 ให้เหลือ U+1F62E) มันก็คือ Emoji 😮 ตัวนี้นั่นเอง

พอจะเห็นภาพของจำนวน Code Points มากขึ้นไหมครับ ว่า Emoji บางตัวหรืออักขระพิเศษบางตัวที่เราใช้ทั้งเป็น Input หรือ Output อาจใช้มากกว่า 1 Code Points ในระบบ UTF-8 ซึ่งมีผลต่อการนับ Character มาตรฐานนี้นั่นเอง
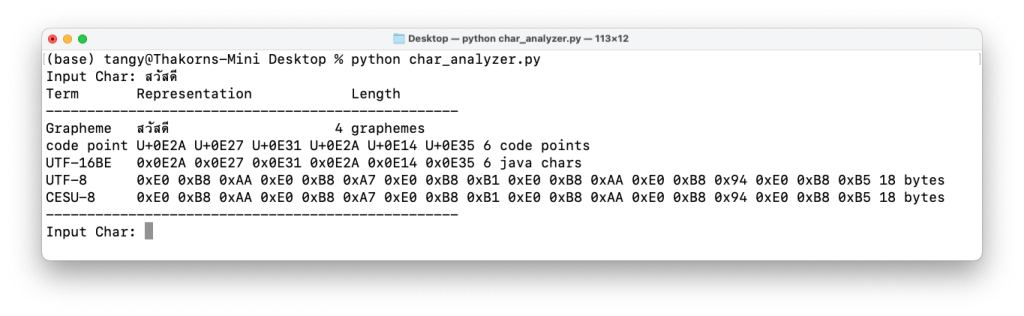
ทีนี้มาสรุปในภาษาไทยกันอีกครั้งหนึ่ง คำว่า “สวัสดี” นับเป็นไทย 6 ตัวอักษร และนับเป็น UTF-8 ได้เท่ากับ 6 Code Points เช่นกันครับ แม้ว่าจะใช้ 18 Bytes แต่เวลาเราใช้ Gemini เรานับเป็น 6 Characters ครับ
ระวังเรื่องสระวรรณยุกต์การผสมคำ!
การผสมคำภาษาไทยต้องเช็กก่อนว่าผสมแบบไหน เช่น คำว่า “กำ” สามารถผสมด้วย 3 Code Points แต่ตามมาตรฐาน W3C จะมีช่องว่างระหว่าง นิคหิต กับ สระอา ดังนั้น ก.ไก่ กับสระอำ จะมีใช้ Code Points น้อยกว่า ก.ไก่, นิคหิต และสระอา ดังตัวอย่างนี้

มาถึงตรงนี้แล้วผมรู้สึกบทความนี้ให้อารมณ์เหมือนกับเราเรียนอักษรศาสตร์มากกว่า Prompt Engineering ครับ แต่อย่างว่าการทำ AI ต้องประยุกต์และเข้าใจหลากหลายศาสตร์ครับ 😀
Conclusion
ผมขอสรุป Key Takeaways ให้ทุกท่านจดจำและนำไปใช้ง่าย ๆ กันดีกว่าครับ
- 1 Character ในภาษาไทย = 1 UTF-8 Points = 1 Character ใน Gemini
- Gemini คิดค่าใช้จ่ายจากจำนวน Characters ของทั้ง Input (Prompt) และ Output (Response)
- ระวังเรื่องสระวรรณยุกต์การผสมคำ!
- ลองใช้โค้ด Python นับตัวอักษรภาษาไทยก่อนได้
- Emoji บางตัวใช้หลาย Code Points
เพียงเท่านี้ผมก็เชื่อว่าทุกท่านสามารถใช้ภาษาไทยกับ Gemini ได้อย่างคลายความกังวลเรื่องขนาด Bytes ที่ใหญ่กว่าภาษาอังกฤษ และก็สามารถคำนวณราคาได้เบื้องต้นตามตัวอย่างในบทความ และจะพบว่า Gemini นี่ทั้งเก่งฉลาดและยังสบายกระเป๋าเป็นมิตรต่อพวกเราชาว Prompt Engineer จริง ๆ นะครับ สำหรับบทความนี้ผมก็ขอจบเพียงเท่านี้ บทความหน้าจะเป็นอย่างไรต่อรอติดตามกันครับ
หากท่านสนใจบริการหรือต้องการคำปรึกษาเพิ่มเติม
ติดต่อเราได้ที่ marketing@tangerine.co.th หรือโทร 094 999 4263
ท่านจะได้รับคำตอบจากผู้เชี่ยวชาญที่ได้รับการรับรองมาตรฐาน

