
สวัสดีชาว Data! พบกันอีกครั้งกับบทความที่ออกแนวไปในทางการทำงานแบบจริงจัง อย่างการสอบ Certification ไม่ว่าจะเพื่อการสมัครงานเดินทางในสายอาชีพนี้ หรือเพื่อ Carrer Path และวันนี้ผมจะมาเล่าเรื่องที่เรียกว่าเป็นกิจวัตรทุก 2 ปีคือการ Recertified Google Cloud Professional Data Engineer ใครที่กำลังมีแผนในการสอบรับรองบทว่าความนี้ช่วยคุณให้มีแรงฮึดไปสอบกันแน่นอนครับ ส่วนใครที่เป็นมือใหม่ป้ายแดงกำลังจะสอบ Data Engineer บทความนี้ก็มีคำตอบให้ทุกท่านเช่นกันครับ
Recertification คืออะไร ? ทำไมต้องสอบ ?
ผมขออนุญาตเกริ่นในเรื่อง Recertify ก่อนที่จะเข้าเนื้อหา Professional Data Engineer กันสักนิดนึงครับ เรื่องราวนี้เริ่มต้นขึ้นเมื่อผมได้รับอีเมลแจ้งให้ทำการต่ออายุ Certificate ตัว Professional Data Engineer ที่สอบไปเมื่อ 31 Jul 2022 ซึ่งการรับรองนี้จะมีอายุ 2 ปี และหมดอายุลงในวันที่ 31 Jul 2024 หมายความว่าหากเราไม่ไปต่ออายุ เราก็ไม่สามารถใช้ Certificate ใบนี้ได้อีกแล้ว
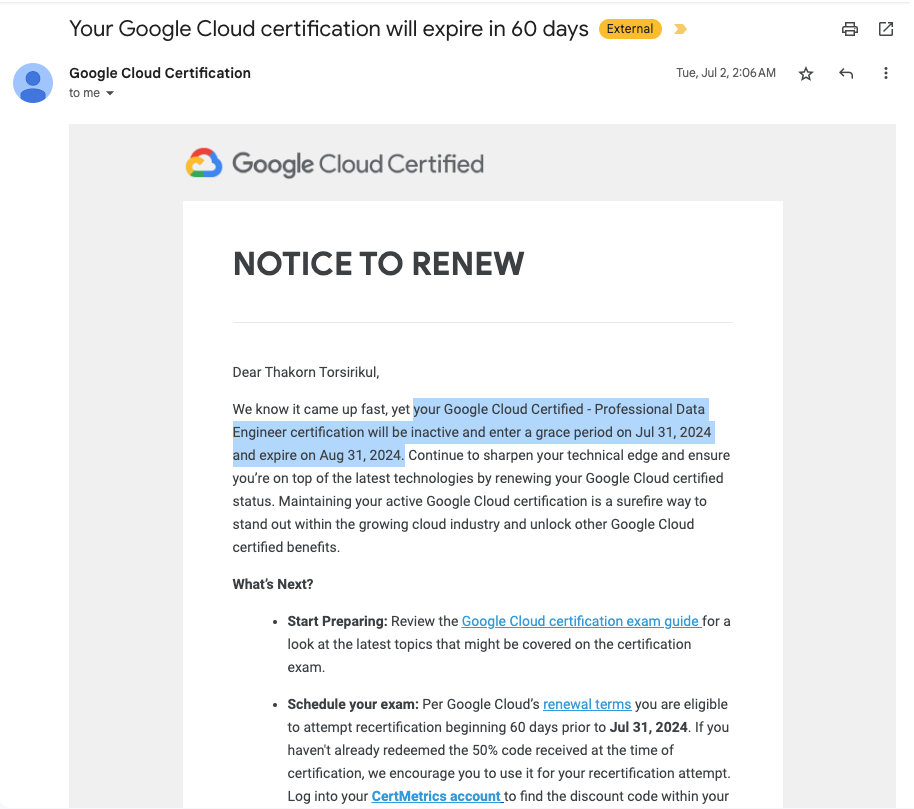

ดังนั้นการ Recertification ก็คือการสอบเพื่อยืนยันความรู้และทักษะของเราอีกครั้งให้อยู่ในช่วงก่อนที่ Certificate จะหมดอายุ เหมือนกับการขยายเวลาเพิ่มไปอีก 2 ปี ซึ่งจริง ๆ ก็คือการสอบใหม่ในชุดข้อสอบที่อัปเดต เพื่อลับคมครับ
แน่นอนว่าทาง Google หรือแม้กระทั่งโลกใบนี้เองก็มีเทคโนโลยีใหม่ ๆ และ Best Practice ที่แนะนำให้ปฏิบัติตาม ซึ่ง 2 ปีที่ผ่านมาความรู้เราอาจจะ Outdate ไปแล้วก็ได้ ถ้า Cert. ที่ไม่มีวันหมดอายุเลย ความสำคัญและการได้มาก็อาจจะไม่ได้เป็นที่ต้องการมากตามอุปสงค์และอุปทานครับ ทำให้การสอบ Recertify นี้จึงสำคัญมาก เพราะว่า :
เทคโนโลยีเปลี่ยนแปลงไว
โลกของ Data เปลี่ยนแปลงตลอดเวลา การ Recertify ช่วยให้เราตามทันเทคโนโลยีใหม่ ๆ เช่น ต่อไปการทำ Data Engineering อาจให้ Generative AI เข้ามาเป็นผู้ช่วยมากขึ้นก็เป็นได้
โอกาสก้าวหน้าและการรับรองทักษะเฉพาะ
การมี Cert. ที่อัปเดตแสดงถึงความมุ่งมั่นและรับรองความสามารถของเรา ทำให้เรามีโอกาสได้เลื่อนตำแหน่งหรือหางานใหม่ที่ดีขึ้น เนื่องจาก Certificate เหล่านี้มีค่าใช้จ่ายในการสอบตั้งแต่ $120 – $250 ซึ่งเป็นมูลค่าไม่น้อย และไม่ได้การันตีว่าเราจะสอบผ่าน ดังนั้นผู้ที่มีใบประกาศเหล่านี้คือตั้งใจไปสอบเพื่อต้องการการรับรองทักษะอย่างแน่วแน่ครับ
มี Benefit อะไรบ้างสำหรับการ Recertification
โดยปกติแล้วหากเราเคยสอบผ่านมาครั้งหนึ่งก็จะได้ Voucher สำหรับเป็นส่วนลด 50% ในการไปสอบใบใหม่หรือ Renew ใบเดิม เราสามารถเข้าไปเอารหัสได้ที่ CertMetrics แล้ว Claim Benefit ได้เลยครับ
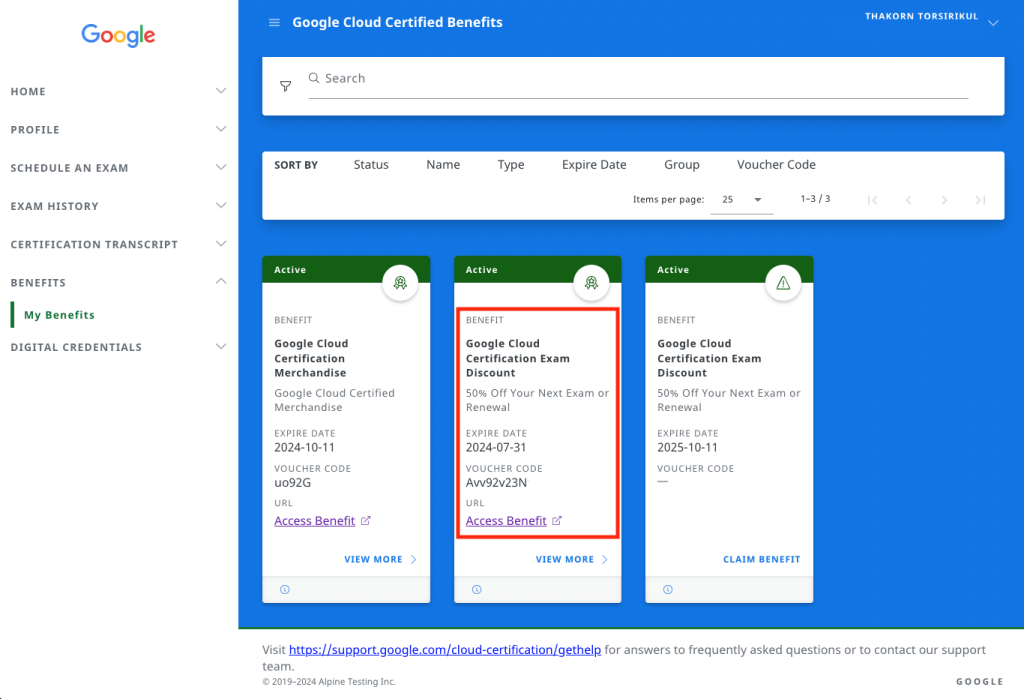
เมื่อได้รหัสสามารถนำไปลงทะเบียนที่ Webassessor ได้เลย ซึ่งถ้าหากใครเป็นมือใหม่ยังไม่เคยสอบ Google Cloud Certificate แนะนำให้ลองอ่าน Blog นี้ครับ ซึ่งเป็นเรื่องราวการสอบแบบปูพื้นฐานในการเป็น Professional Machine Learning Engineer รวมถึงสนามสอบ

Professional Data Engineer คืออะไร ?
ต้องกล่าวก่อนว่า Data Engineer คือผู้ที่ทำให้องค์กรสามารถนำข้อมูลไปใช้ได้อย่างมีประสิทธิภาพและเกิดประโยชน์สูงสุด โดยทำหน้าที่ตั้งแต่การเก็บรวบรวมข้อมูล การแปลงข้อมูล ไปจนถึงการเผยแพร่ข้อมูล (Data Pipeline) ต้องมีความสามารถในการออกแบบ สร้าง และจัดการระบบประมวลผลข้อมูลขนาดใหญ่ (Big Data Processing)
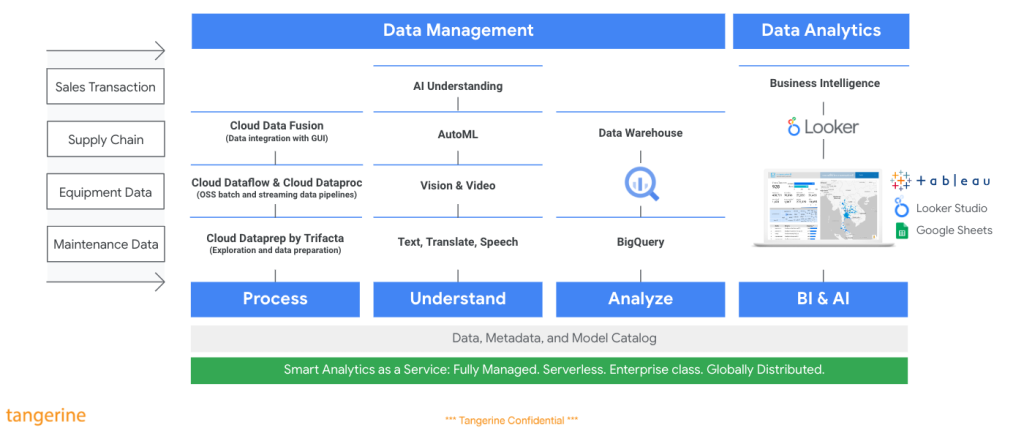
ซึ่ง Cert. นี้จะช่วยยืนยันความสามารถของเราในด้านการทำ Data Management ตลอดจนการนำไปใช้ประโยชน์ เช่น งาน Data Analytics & AI ครับ
Professional Data Engineer กับ Professional Machine Learning ต่างกันอย่างไร ?
ความเหมือนและแตกต่างระหว่าง Professional Data Engineer กับ Professional Machine Learning ทั้งสอง Cert. นี้มีความเกี่ยวข้องกัน แต่ก็มีความแตกต่างกันอยู่ เช่น
เป้าหมายและการมุ่งเน้น
- Professional Data Engineer : เน้นที่การออกแบบและสร้างระบบประมวลผลข้อมูลขนาดใหญ่ การจัดการ Data Pipeline และการทำ Data Warehousing
- Professional Machine Learning Engineer : เน้นที่การออกแบบ สร้าง และปรับแต่ง Machine Learning Model เพื่อแก้ปัญหาทางธุรกิจ
ทักษะที่ต้องมีของ Professional Data Engineer
- Data Engineering : การออกแบบ Data Pipeline, ETL (Extract, Transform, Load) Process, การทำ Data Warehousing และ Data Lake
- Infrastructure : ความเข้าใจใน GCP Services ต่าง ๆ เช่น BigQuery, Dataflow, Dataproc, Cloud Storage
- Programming : Python หรือ Java สำหรับเขียน Data Pipeline
- Database : SQL สำหรับ Query ข้อมูล
ทักษะที่ต้องมีของ Professional Machine Learning Engineer
- Machine Learning : ความเข้าใจใน Machine Learning Algorithms ต่าง ๆ การทำ Feature Engineering, Model Selection และ Model Evaluation
- Deep Learning : ความรู้พื้นฐานเกี่ยวกับ Neural Networks และ Deep Learning Frameworks เช่น TensorFlow
- MLOps : การทำ Continuous Training และ Continuous Deployment ของ Machine Learning Model
- Infrastructure : ความเข้าใจใน GCP Services ที่เกี่ยวข้องกับ Machine Learning เช่น Vertex AI Platform, BigQuery ML และ AutoML
เลือกเส้นทางไหนดีระหว่าง Data Engineer หรือ ML Engineer ?
การเลือกสอบหรือเลือกอาชีพของสองสายนี้เป็นไปตามความชอบครับ แต่ถ้าหากคุณชอบทั้งคู่เป็น Fullstack Data Scientist สอบทั้งคู่เลยก็ไม่เลวนะครับ แต่ผมอยากให้เริ่มที่ Data Engineer ก่อนที่พื้นฐานน่าจะดี แต่หากต้องการเลือกทางเดินสักทางผมก็มีไกด์มาให้ครับ
ถ้าหากเราชอบ…
- การออกแบบและสร้างระบบประมวลผลข้อมูลขนาดใหญ่
- การจัดการ Data Pipeline และ Data Warehouse
- การเขียนโปรแกรมเพื่อประมวลผลข้อมูล
เลือก : Google Cloud Professional Data Engineer
แต่ถ้าหากเราชอบ…
- Machine Learning และ Deep Learning
- การสร้างและปรับแต่ง Model
- การแก้ปัญหาทางธุรกิจด้วย Machine Learning
เลือก : Google Cloud Professional Machine Learning Engineer
เตรียมตัวสอบกันอย่างไรดีกับ Professional Data Engineer!
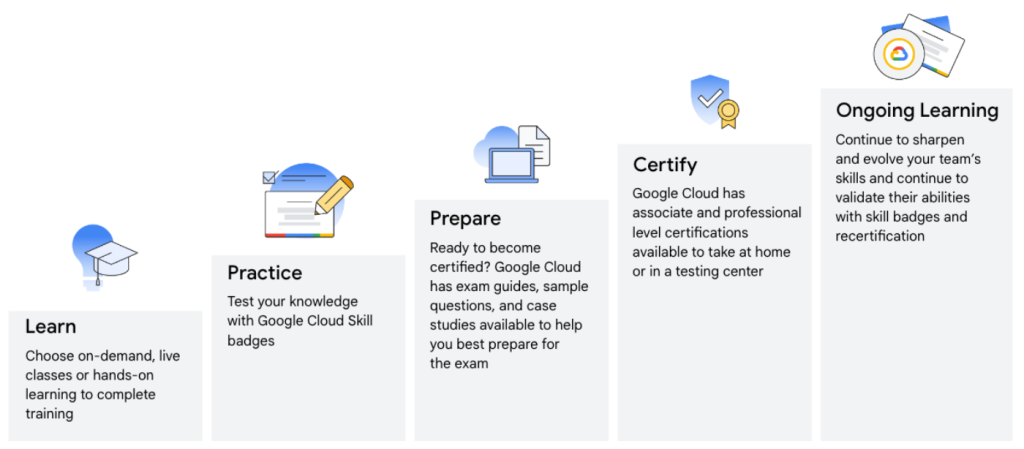
จริง ๆ แล้วการเตรียมตัวสอบของทุก Google Cloud Certificate จะคล้ายกันคือ เรียนรู้ ฝึกฝน และเตรียมตัวไปสอบครับ จะต่างกันที่เนื้อหาการสอบมากกว่า ดังนั้นเรื่องการเตรียมตัวพื้นฐานผมแนะนำให้อ่านจากการสอบ Machine Learning Engineer ส่วนในบทความนี้ผมจะเน้นไปทางข้อเสนอแนะและทริคเพิ่มเติมครับ
การเลือกสนามสอบ
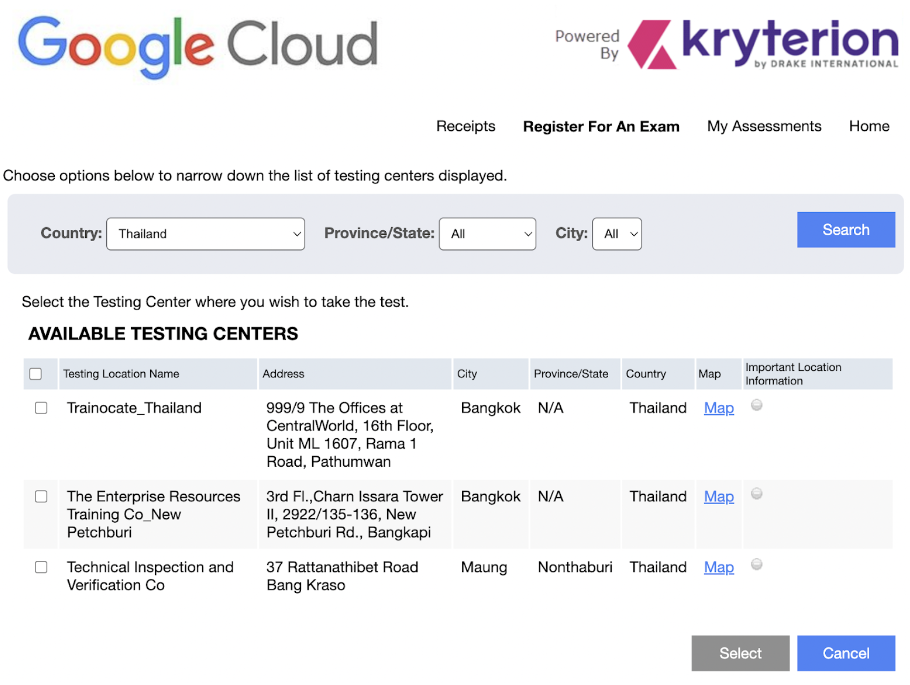
จังหวะที่เราลงทะเบียนเราสามารถเลือกสนามสอบตามวันและเวลาที่ Available แต่ละชุดข้อสอบครับ ในชุดข้อสอบ Data Engineer เดียวกัน บางสนามก็อาจจะปิด หรือบางช่วงเวลาอาจจะไม่มี ให้เลือกสนามที่เราสะดวกครับ
สำหรับผมทั้งสองสนามคือ Trainocate กับ Enterprise Resources Training (ERT) นั้นไม่ค่อยไกลกันมาก หากเน้นรถไฟฟ้าก็แนะนำไปที่ Trainocate เพราะอยู่ชั้น 16 ตึก The Offices @Central World ครับ แต่ถ้าเน้นขึ้นบันไดเลื่อนไม่กี่ชั้นก็เป็น ตึกชาญอิสระ ทาวเวอร์ 2 ที่ ERT ครับ
บรรยากาศในห้องสอบอาจแตกต่างกันนิดนึง ทาง Trainocate จะกั้นเป็นห้องไว้ขนาด 1 ท่าน มีที่ครอบหูไว้กันเสียงภายนอก สามามารถใส่จังหวะที่ต้องใช้สมาธิครับ (ส่วนตัวผมใส่ตลอดการสอบ) แต่ถ้าเป็น ERT จะไม่มีที่กันเสียงให้ และไม่ได้แบ่งห้องครับ ถ้ามีคนอื่นมาสอบด้วย ก็จะได้นั่งข้าง ๆ กัน อาจทำให้เสียสมาธิได้ ถ้าใจเราไม่นิ่งพอนะครับ
แนวข้อสอบ Professional Data Engineer
ข้อสอบฉบับอัปเดตปี 2024 มีความยากขึ้นเล็กน้อยครับ เพราะเทคโนโลยีมีการอัปเดตรวมถึง Tools ใหม่ ๆ บน Google Cloud แต่ก็ไม่ได้ไกลเกินตัวเราครับ มีข้อสอบอยู่ 50 ข้อกับเวลาทำ 2 ชั่วโมง โจทย์เป็นภาษาอังกฤษต้องใช้เวลาอ่าน + ตอบ ไม่เกิน 2 นาทีครึ่ง หากใช้เวลาเกินกว่านี้จะรีวิวและส่งข้อสอบไม่ทันครับ และจะรู้ผลสอบทันทีเลยว่า Pass / Fail แต่เวลาเราสอบจริง ๆ ถ้าเราทำข้อสอบได้แต่ละข้อจะใช้เวลาอ่านและตอบน้อยมาก อาจจะเหลือสัก 30 นาที มารีวิวที่เราตอบแต่ละข้ออีกทีก็ได้ครับ
ผมขออนุญาตอ้างอิงแต่ละหัวข้อตามเว็บ Certification Exam Guide จากทาง Google พร้อมเพิ่มตัวทริคและความคิดเห็นส่วนตัวจากที่ไปสอบมาด้วยนะครับ
Section 1 : Designing Data Processing Systems (~22% of the exam)
1.1 Designing for Security and Compliance
หัวข้อนี้คือการออกแบบให้ตรงตาม Security และ Compliance แต่ละที่ เราอาจจะต้องรู้จัก HIPPA, PCI DSS แต่ชื่อเหล่านี้ไม่ออกครับ จะออกแนว Compliance ที่ในแต่ละองค์กร Define ขึ้นมา เช่น ต้องมีการเข้ารหัสใน Table นี้ จะมีเพียงทีม Finance ที่เข้าถึงตัวเลขนี้ได้ ส่วนที่อื่นเข้าไม่ได้ ต้องทำอย่างไร
ผมว่าเรื่อง Key นี่ออกเยอะ เช่น การใช้ KMS จัดการ Key หรือการใช้ Hardware Security Modules (HSMs) เข้ามาด้วย ในส่วน DLP ก็ออกค่อนข้างเยอะน่าจะประมาณ 4 ข้อ เป็นเรื่องของการหยิบใช้ DLP ให้เหมาะสมครับ ว่า De-identify แบบใด หรือหยิบใช้ DLP คู่กับ Service อะไร เช่น ใช้ Dataplex สแกนหา Sensitive Data หรือการเข้ารหัสนี้ควรใช้ AEAD Functions แทนไหม ด้วยข้อจำกัดอะไรบ้างครับ
แต่ที่อยากให้เพิ่มเติมอีกนิดนึงคือการพิจารณา Data Sovereignty หรือ Data Residency ด้วยว่าเป็น Single Region หรือ Dual Region ถ้าเป็น dual-regions ทำ DR/DC ไหม ใช้ turbo replication ดีหรือเปล่า ก็ต้องอ่านเงื่อนไขที่โจทย์กำชับครับว่าเขาจำกัดอะไรบ้าง เช่นจำกัดว่า RPO = 15 ต้องมี Job มาเช็กใน Period เวลาเท่าไร
1.2 Designing for Reliability and Fidelity
หัวข้อนี้เท่าที่ผมเจอจะเน้นถาม Tools อยู่ 4 ตัวนี้คือ Dataprep, Dataflow, Dataproc และ Data Fusion เราต้องรู้จักความเหมาะสมแต่ละอันที่ Data Fusion อาจจะมี Cost ที่สูงกว่าเพื่อน ๆ แต่ใช้งานง่ายครบครันทุกการทำ Data Pipeline ข้างหลังบ้านเป็น Dataproc แต่ถ้าเน้น Prep Data เร็ว ๆ แบบ No-Code ก็ Dataprep หากเน้น Scale รับ Real-time ได้ก็พิจารณา Dataflow ครับ จุดตัดข้อนี้ต้องสังเกต Keyword ว่า Real-time หรือ Batch จะได้เลือก Tools ถูกด้วย เพราะอย่าง Apache Spark / Dataproc เราก็เน้นทำงานเป็น Job ไม่ได้ Real-time
1.3 Designing for Flexibility and Portability
หัวข้อนี้เป็นการถามเรื่องออกแบบให้มันยืดหยุ่นและตรงกับ Requirements เช่น การใช้ Tools อย่างพวก Dataplex ในการออกแบบ Data Staging ต่าง ๆ ตัวอย่างเช่น หากองค์กรเรามี 3 BUs แยก แต่ละ BUs มีทั้งทีม Data Scientist และ Data Engineer เราควรทำเป็น Lake บน Dataplex กี่ lake และแบ่งเป็นกี่ Zone ตามทีมหรือตาม BUs ดีถึงจะเหมาะสม
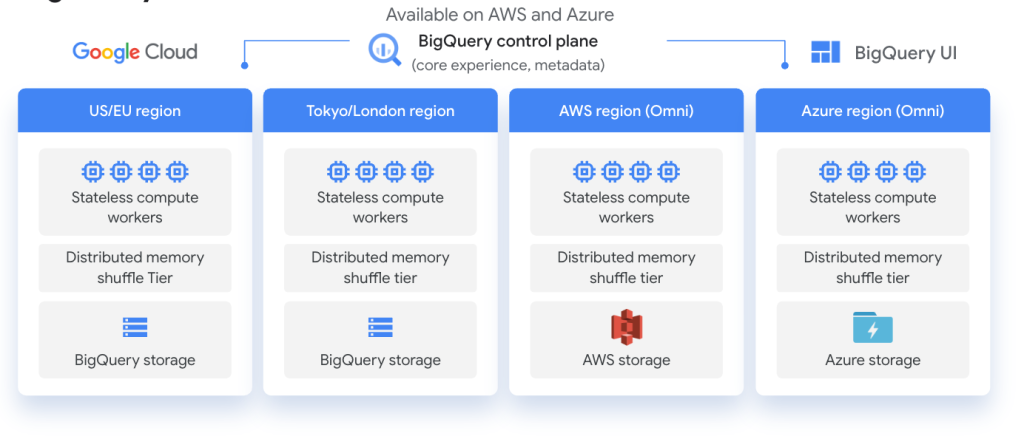
ส่วนเรื่องการออกแบบเป็น Multi-cloud ควรจะนึกถึงด้วยครับ ตรงนี้จะมีโจทย์ที่ใช้พวก BigQuery Omni ไปด้วย ซึ่งจะได้ลำเลียงหรือเขียนข้อมูลไปที่ Lake ค่ายขึ้นได้ง่าย แต่ต้องอยู่บน Region US โจทย์ก็จะมีเงื่อนไขเหล่านี้ให้เราตัดสินใจเลือกครับ
1.4 Designing Data Migrations
การ Migrate Data หรือ Transfer Data เราต้องเข้าถึงเครื่องมือที่ Transfer ข้อมูลอย่างเหมาะสม เช่น Data Transfer Service เน้นไปที่ Cloud Storage แต่ถ้า BigQuery Transfer Service ก็คือเข้า BigQuery เราต้องดู Keyword ของชื่อ Tools กับปลายทางด้วยเพื่อระวังโจทย์หลอกครับ
ผมจำได้ว่าจะมีถามเกี่ยวกับ Datastream 1-2 ข้อ แต่อยู่ในรูปของตัวเลือกไม่ใช่โจทย์ครับ ซึ่งโจทย์ข้อนี้ก็จะถามเกี่ยวกับการ Migrate Oracle มันก็จะมีหลาย Solution ตั้งแต่ใช้ Datastream ลำเลียงข้อมูลหรือตั้งเครื่องบน GCP แบบ Bare Metal
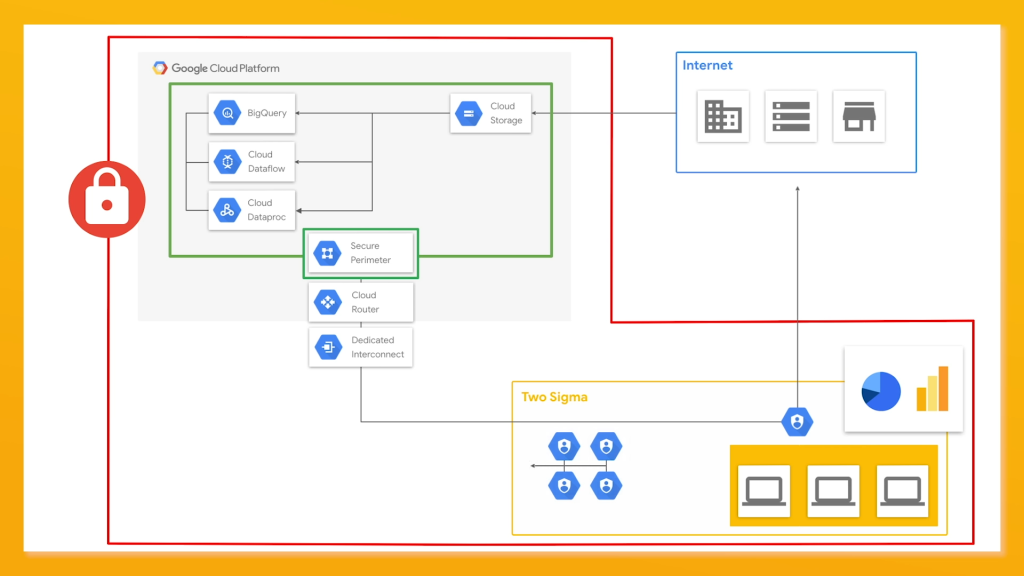
ซึ่งก็จะมีเรื่องที่เกี่ยวกับ Network อีก เช่น Private Network, Service Perimeter, VPC, Site-to-site Network, CIDR Network Address เน้นความเข้าใจและควบคุมการเชื่อมต่อทางเข้าของ Network ซึ่งข้อที่เป็น Network ออกประมาณ 1-2 ข้อครับ
Section 2 : Ingesting and Processing the Data (~25% of the exam)
2.1 Planning the Data Pipelines
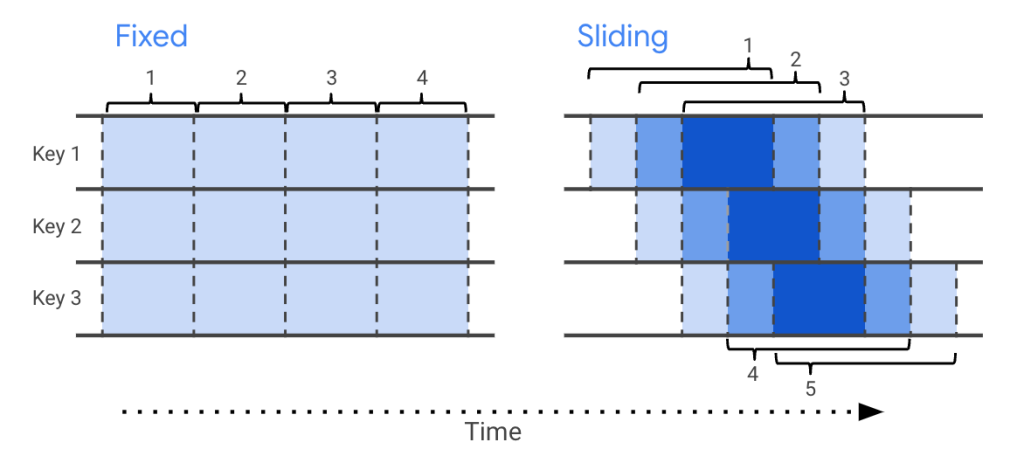
หัวข้อนี้เริ่มเป็นการออกแบบแล้ว เช่น มีอุปกรณ์ตรวจ Noise ที่ไซต์ก่อสร้างว่ากี่เดซิเบล จากนั้นจะส่งข้อมูลมาเป็น Real-time เราจะต้องทำให้การหาค่าเฉลี่ยนั้นใน Period 15 นาที แต่หากไม่มี Noise มาใน 30 นาทีจะถือว่าไม่นำมาคิด ถ้าเจอแบบนี้เราก็รู้แล้วว่าควรใช้ Dataflow เพราะรองรับ Real-time และก็ไปดูว่าต้องใช้ Windowing แบบไหน Fixed, Sliding, Session หรือ Global Windows แต่ถ้าภาษา Dataflow ตัว Fixed Windows ก็คือ Tumbling Windows, ตัว Sliding Windows ก็เป็น Hopping Windows เป็นต้น
2.2 Building the Pipelines
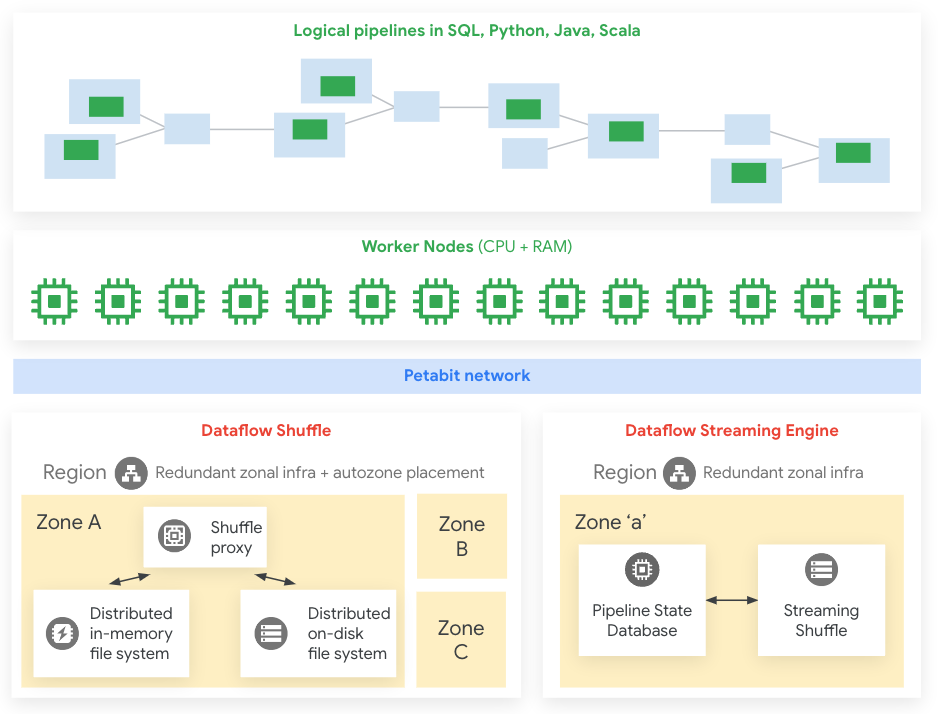
หัวข้อ Pipeline อยากให้แน่น ๆ ตรง Spark ออก 3-4 ข้อเลย คืออย่างเช่น ถ้าใช้ Spark ที่ไม่ต้องติดตั้ง Infrastructure ก็ควรใช้ Dataproc Serverless แต่โจทย์เป็นเรื่องราวคงไม่ตาม Spark ง่ายแบบนี้ครับ เราก็ต้องเข้าใจก่อนว่า Spark มันมี Cluster แต่ถ้าอยากยืดหยุ่นรับ Real-time ก็ลองมองไปที่ Dataflow ครับ ตัว Dataflow ลองดูเรื่อง Dataflow Prime ด้วยนะครับ
เรื่อง Real-time มีถามค่อนข้างเยอะดังนั้นให้ดูตาม Source ที่เหมาะสม และศึกษา Pub/Sub, Apache Kafka ด้วยเพราะมีข้อที่ Concern ในเรื่อง Latency ดังนั้นเราควร Migrate ไปใช้ Pub/Sub หรือใช้ Kafka อยู่แล้วที่เป็น Existing ต้องสังเกตจากโจทย์ครับ ไม่ใช่ว่าทุกอันเปลี่ยนไปใช้ Google แล้วจะถูกต้องทุก Use-case บางอันก็อาจใช้ Open Source ครับ
อย่างตัว Dataflow เองก็มาจาก Beam ดังนั้นก็ต้องเข้าใจ Beam ครับ เช่น การใช้ Reshuffle ในการปรับ Parallelism เพื่อให้แบ่งงานกับ Worker สมดุลกันไม่เป็นคอขวด หรือทำให้ได้ปริมาณงานใกล้เคียงกันก็สามารถเพิ่มประสิทธิภาพการประมวลผลแบบขนานได้แล้ว และการป้องกันอีกเหตุการณ์ เช่น Coupled Failures ที่การทำ Distrubuted Processing มีปัญหาเนื่องจาก Worker ตัวหนึ่งตายไป ก็ไปทำให้เพื่อน ๆ ตายตามทำงานไม่ได้ ดังนั้นแต่ละตัวควรได้งานที่ใกล้เคียงกันครับ แต่ก็เช็กด้วยว่า Memory หรือ Resources แต่ละตัวเหมาะสมหรือไม่ ในส่วนนี้มีออกสอบครับ
2.3 Deploying and Operationalizing the Pipelines
อีกเรื่องที่สำคัญในการ Deploy เพราะ Data Engineer บางคนอาจลืมเรื่อง CI/CD และคิดว่าเป็นเรื่อง DevOps บอกได้เลยว่าต้องรู้บ้างครับ เช่น การใช้ Composer Orchestrate งานหรือการใช้ Cloud Run ซึ่งข้อนี้ออกน้อยครับ และไม่ยากมากเหมือนเป็นข้อแจกคะแนนครับ
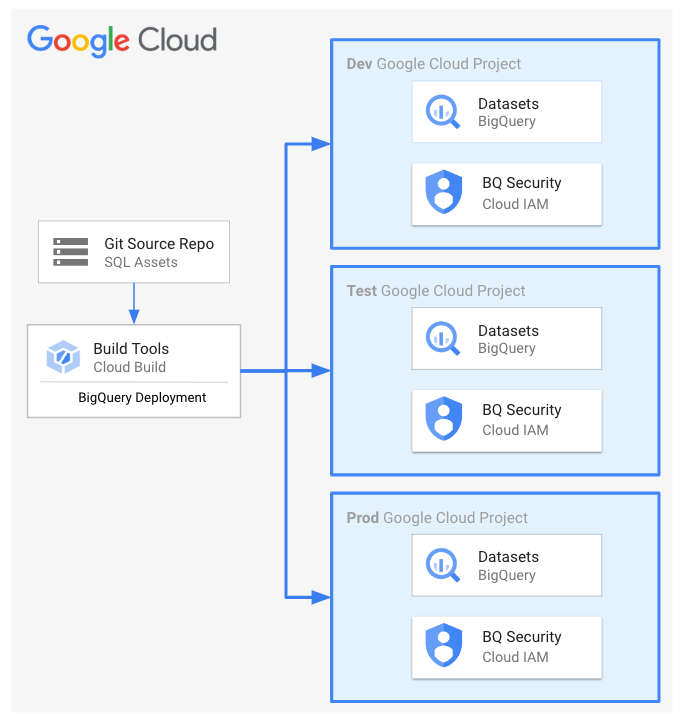
Section 3 : Storing the Data (~20% of the exam)
3.1 Selecting Storage Systems
หัวข้อนี้เป็นการเลือก Storage ที่เหมาะสมไม่ว่าจะเป็น Cloud Storage, BigQuery, Bigtable, Spanner, Cloud SQL, Firestore และ Memorystore ล้วนจัดกระบวนทัพมาเต็มครับ ทั้งนี้ขึ้นอยู่กับโจทย์แล้วว่าต้องการ Database แบบใด เช่น ถ้าองค์กรเราใช้ Hadoop อยู่อยากขยับมาบน Cloud ก็ควรเลือก GCS ครับ หรือถ้า Bigtable ควรออกแบบ Schema อย่างไร พวก Row Key นี่ออกทุกครั้งเลยนะครับ ผมยังไม่เจอครั้งไหนไม่ออก

พวก Memorystore for Redis, Memorystore for Memcached ก็ออกประมาณ 2 ข้อครับ มีตัวเลือกหลอกเยอะต้องดูตัวเลขดี ๆ ครับ นอกจากนี้ยังมีการบริหารตัว Lifecycle ของข้อมูล เช่น บริษัทเก็บข้อมูลแค่ 90 วัน นอกนั้นเราก็ต้องลบอัตโนมัติ จะไปตั้งค่ายังไง เช่น ใช้ Policy บน Cloud Storage ปล่อย Expire ดี หรือไปกำหนด Partition ให้ Expire บน BigQuery ก็ขึ้นอยู่กับว่าข้อมูลนี้เป็น Files หรือเป็น Table ถูกต้องไหมครับ
3.2 Planning for Using a Data Warehouse
หัวข้อเรื่องนี้คงเป็นเรื่องหวานหมูสำหรับ Data Engineer เพราะมุ่งเน้นที่ Data Warehouse เป็นหลัก นั่นก็คือ BigQuery ครับ ลองดูในเรื่องการจัดการข้อมูลเช่น BigQuery Time Travel, BigQuery Snapshot รวมถึงแอบมี Dataform สำหรับคนถนัด ELT แทนการเขียน Python ด้วย หรือเป็นคำถามเชิงคิดวิเคราะห์ต่อ อย่าง BI Engine ต่างจาก Memory Caching ยังไง
3.3 Using a Data Lake
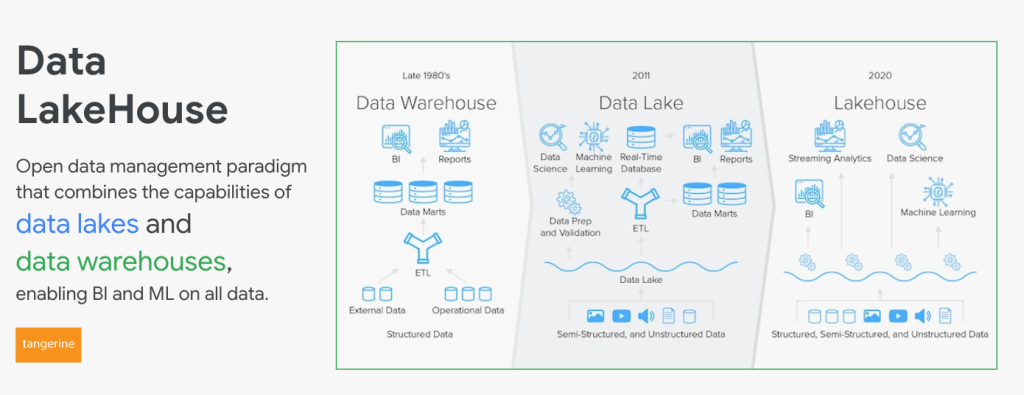
Data Lake ก็มีออกที่เกี่ยวกับ Source ประเภท CSV, Parquet เราก็นึกถึง Lake กันเป็นหลัก แต่ผมว่าข้อสอบที่เกี่ยวกับ Lake ค่อนข้างจะตายตัวซ้ำกันคิดว่าพอจะเดาคำตอบกันได้ เพราะอนาคตเราก็น่าจะไปใน Concept Lakehouse กันมากกว่า รวมถึงการทำ ELT บน BigQuery ก็ง่ายกว่ามาก แต่อย่างไร Data Lake ก็ยังคงจำเป็นในกลุ่ม Data Engineer ที่ประมวลผลข้อมูลที่มหาศาลจากหลาย ๆ Source อยู่ดีครับ แค่อยากเล่าให้เพื่อน ๆ ฟังว่า คำถามไม่ได้มีลูกเล่น และความซับซ้อนมากนักสามารถตอบได้จากสัญชาตญาณครับ
3.4 Designing for a Data Mesh
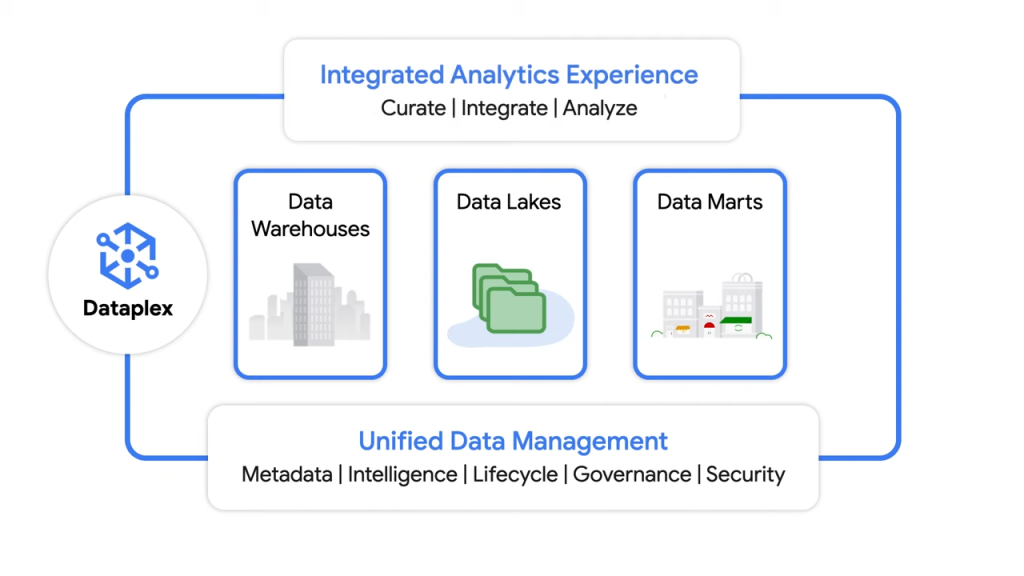
Data Mesh พระเอกหลักของงานนี้คงหนีไม่พ้น Dataplex ครับ พยายามดู Concept Data Governance, Data Quality ต่าง ๆ การใช้แบ่งทีมและใช้ประโยชน์จากข้อมูลที่เป็นศูนย์กลางครับ ข้อสอบ Dataplex จะใกล้เคียงกับ Spark เพราะบนนั้นเรา Start ตัว SparkQL และ Cluster ต่าง ๆ โดยแยกออกมาเป็น Lake เป็น Zone เลย ลองศึกษา Dataplex ได้จากบทความนี้ครับ

Section 4 : Preparing and Using Data for Analysis (~15% of the exam)
4.1 Preparing Data for Visualization
หลังจาก Part Data Management ก็เข้าถึงส่วนของการนำไปใช้ประโยชน์ต่อคือ Visualization ครับ โจทย์ก็จะมีเรื่องของการควบคุม Access ดี ๆ ไม่ว่าการใช้ IAM หรือ DLP ก่อนเตรียมไปบิด Dashboard หัวข้อนี้มี BigQuery Materialized Views ออกสอบด้วยนะครับ ลองดูว่าการคุม Access นี้ใช้ตัวไหนเหมาะสม
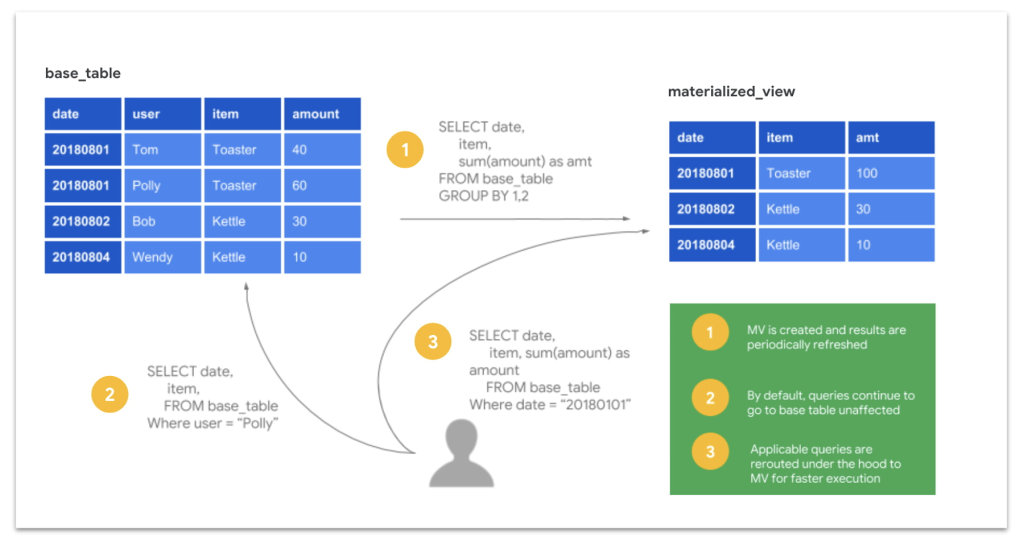
4.2 Sharing Data
ในการ Sharing ขอให้นึกถึงผู้ใช้เป็นหลักครับ ถ้าผู้ใช้ถนัด Spreadsheets ก็ให้ใช้ Connected Sheets ต่อไป BigQuery หรืออยากได้แบบ Dashboard ก็ต้องเป็น Looker Studio หรือหากแชร์ให้ Partner ของเราไปใช้ต่อก็อาจจะมองเป็น Analytics Hub บน BigQuery ที่ง่ายและเร็วที่สุดครับ ตรงนี้ให้เลือกวิธีการแชร์ตามกลุ่มผู้ใช้ที่โจทย์ระบุไว้นะครับไม่ยากมาก
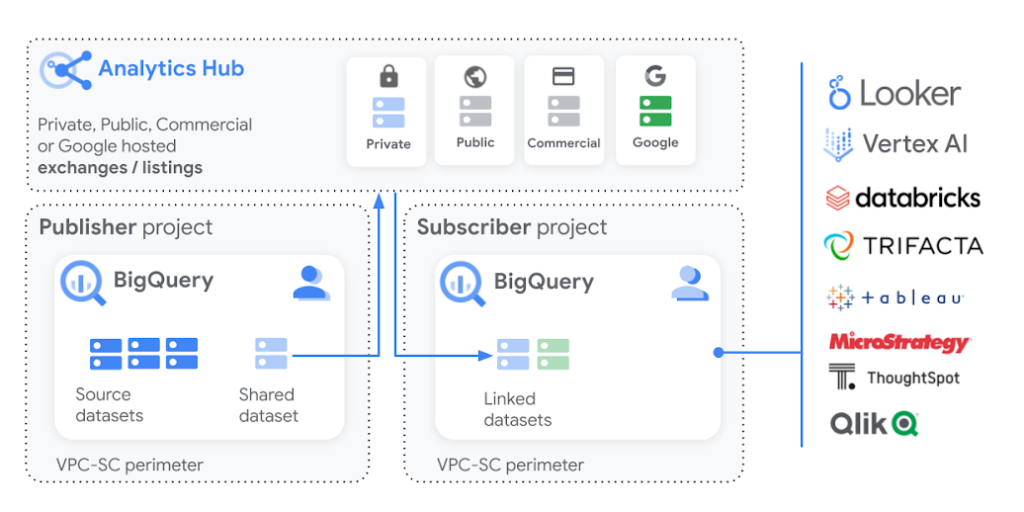
4.3 Exploring and Analyzing Data
เป็นการเตรียม Feature Engineering และอื่น ๆ เพื่อใช้ในเชิงการทำ Machine Learning Model ต่อไปครับ ส่วนการเตรียมน่าจะออกประมาณ 1 ข้อ เช่น ทีม Data Science จะเตรียม Data ไปทำ Model ซึ่งต้องการ Prepare เองแต่ไม่ถนัดเขียนโค้ด หากเจอแบบนี้ก็ใช้แนว Drag & Drop เช่น Dataprep ช่วยเตรียมก็จะเหมาะสมครับ
Section 5 : Maintaining and Automating Data Workloads (~18% of the exam)
5.1 Optimizing Resources
เรื่องการ Optimizing หลัก ๆ มีสองแบบ ไม่ Cost ก็ Performance เราก็ต้องปรับจูนให้ตรงตาม Business ว่าแบบใดเหมาะสม เช่น การคุม Cost บน BigQuery ให้ Effective ควรตั้งค่า BigQuery Editions ในการ Reservation อย่างไร ? เป็นต้น
5.2 Designing Automation and Repeatability
การออกแบบให้ Pipeline ของเรามัน Auto และสามารถใช้ซ้ำได้ส่วนใหญ่คือการออกแบบ DAGs บน Cloud Composer ครับ เช่น การรองรับ Trigger หรือ Schedule เพื่อให้ Workflow ทำงานอัตโนมัติ
5.3 Organizing Workloads Based on Business Requirements
ข้อนี้คล้าย ๆ 5.1 ครับ
5.4 Monitoring and Troubleshooting Processes
หัวข้อนี้ออกประมาณ 1-2 ข้อ ในการ Troubleshoot ปัญหาที่เกิดขึ้นว่าไปเริ่มดูจากตรงไหนดี เพื่อ Scope หรือแก้ไขไปเลยครับ
5.5 Maintaining Awareness of Failures and Mitigating Impact
หัวข้อนี้เป็นความรู้ในลักษณะที่ป้องกัน Impact ที่เกิดขึ้นจากการ Fail ซึ่งที่ผมเจอคือการแก้ไข Failover หรือการ Retry ครับ เมื่อ Data ส่งมาไม่ถึงควรตั้ง Retry ที่ฝั่งไหน เช่น Dataflow หรือ Pub/Sub แล้วต้องไปเช็กข้อมูลที่หายกับทีมไหน เช่น ทีมที่ทำข้อมูล กับทีมที่รับข้อมูลมาส่งต่อเป็นคนละทีมกัน ข้อมูลที่หายไปควรจะไปเช็กทีมต้นทางที่ดูแล Pub/Sub ก่อนว่าได้รับครบถ้วนไหม ก่อน Retry Pipeline ครับ เพราะถ้าต้นทางหาย Retry ไปก็ไม่เจอข้อมูลอยู่ดี เป็นต้น
ลองทำแนวข้อสอบ Professional Data Engineer
เป็นอย่างไรบ้างครับแนวข้อสอบข้างต้นที่ผมลิสต์ให้ คิดว่าพอจะเป็นแนวทางในการสอบหรือไปเรียนรู้แต่ละหัวข้อได้ง่ายขึ้นใช่ไหมครับ ทีนี้เรามาลองทำแนวข้อสอบกันบ้างดีกว่า โชคดีที่ทาง Cloud Skills Boost มีคอร์สที่เตรียมตัวเป็น Professional Data Engineer แบบไม่เสียค่าใช้จ่าย เรียนจบก็จะได้ Badge ไป Enroll ได้เลยครับ
ทีนี้แต่ละ Module จะมีการวัดความรู้ตรง Diagnostic Questions ลองเข้าไปทำได้ครับจะได้รู้ว่าเราควรอ่านตรงไหนเพิ่ม
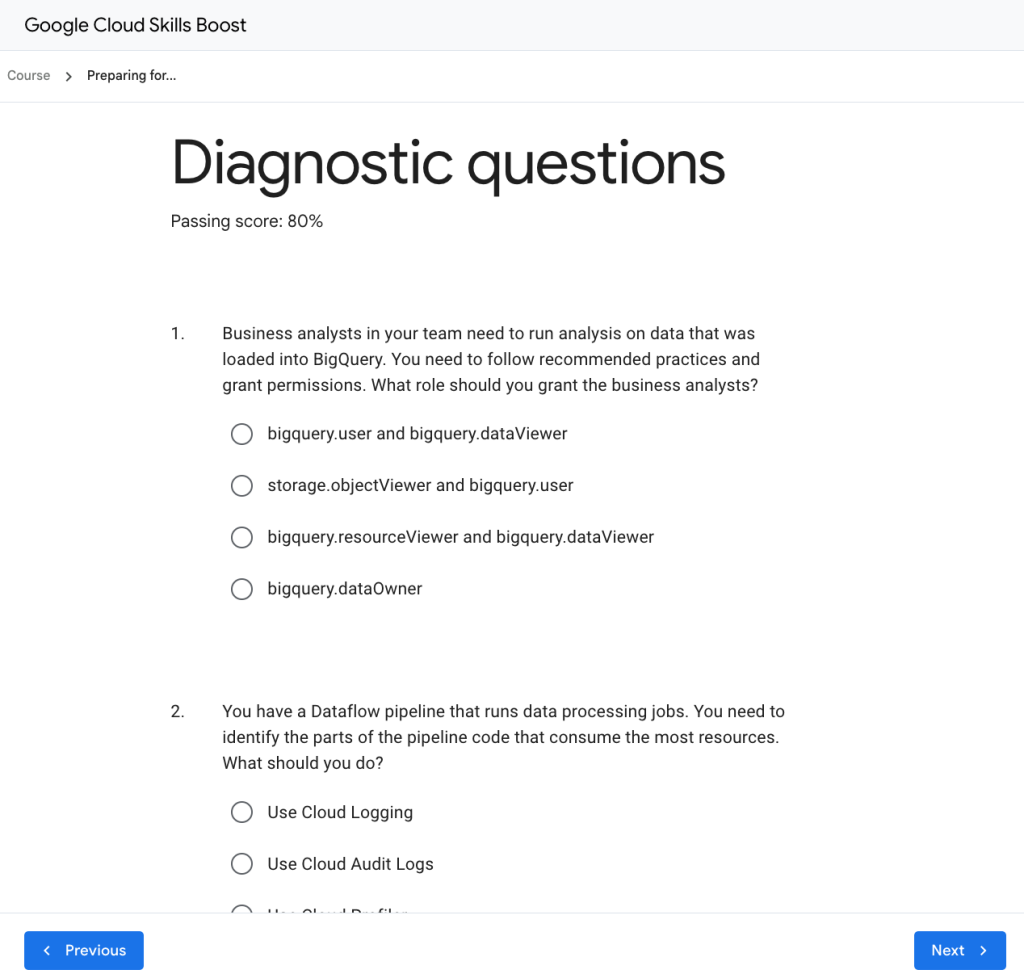
Swag สุดเท่ รับไปเลยเมื่อพิชิต Google Cloud Certification!
นอกจากความภาคภูมิใจและใบ Certificate แล้ว การสอบผ่าน Google Cloud Certification ยังมีของรางวัลสุดพิเศษรอคุณอยู่ด้วยนะ! ของรางวัลเหล่านี้เรียกว่า “Swag” ซึ่งเป็นคำสแลงที่แปลว่า “ของที่ระลึกสุดเท่” นั่นเอง
Swag ที่เราอาจได้รับ (ขึ้นอยู่กับเงื่อนไขและช่วงเวลา)
- เสื้อแจ็คเก็ต Google Cloud : อุ่นกายสบายใจ แถมเท่สุด ๆ
- กระเป๋าเป้ Google Cloud : ใส่โน้ตบุ๊กไปทำงานได้สบาย ๆ
- ขวดน้ำ Google Cloud : ดื่มน้ำให้ชุ่มคอพร้อมรักษ์โลก
- สติกเกอร์ Google Cloud : เอาไปแปะโน้ตบุ๊กหรือกระเป๋าเพิ่มความเท่
- และอื่น ๆ อีกมากมาย : Google Cloud อาจมีเซอร์ไพรส์อื่น ๆ รอคุณอยู่
วิธีรับ Swag จาก Google Cloud
- สอบผ่าน Google Cloud Certification : เราจะทราบผลหลังสอบทันที แต่ได้รับเป็นทางการจาก Google ผ่านทางอีเมลไม่เกิน 7 วัน สำหรับการสอบครั้งนี้ผมสอบวันอังคาร และได้รับเมล์รับรองวันศุกร์
- รอรับอีเมล : ในอีเมลจะยินดีกับเรา และมีให้ไปเช็ก Benefits ใน CertMetrics ครับ ในนั้นจะมีโค้ด Swag ให้
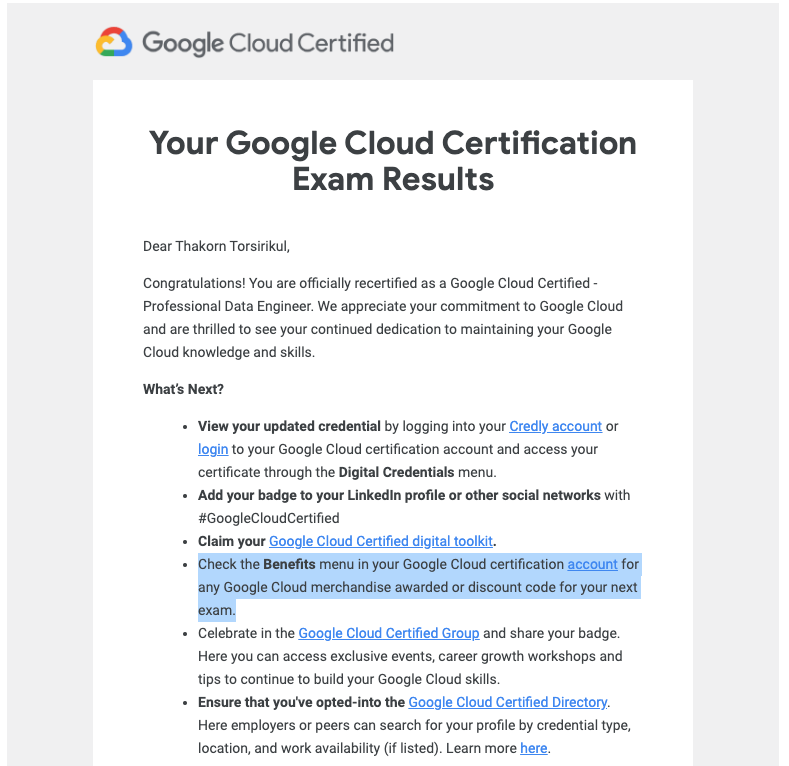
3. เก็บโค้ด : หลังจากเข้าไปที่ CertMetrics ในเมนู Benefits อันเดิมจะมีกล่องเพิ่มมาให้สำหรับใช้รับ Swag จาก Google Cloud Certications Merchandise
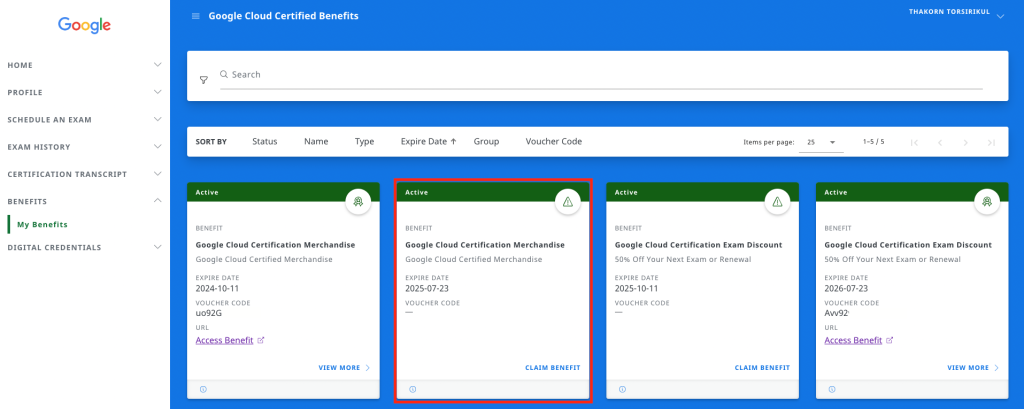
4. กรอกโค้ด : แล้วเลือกของรางวัลสุดเท่ได้เลยครับ ครั้งนี้จะเน้นเสื้อแจ็คเก็ตเยอะเหมือนกัน

ถ้าเลือกชุดแก้วน้ำก็จะมีสติกเกอร์น่ารัก ๆ แปะหลัง Laptop ด้วยครับ ส่วนคุ้มค่าหน่อยผมว่าน่าจะเป็นกระเป๋า Timbuk2 แต่หากใครมีกระเป๋าเยอะแล้วก็เลือกแจ็คเกตสักตัวก็เท่ไม่หยอกครับ
5. รอรับ Swag : Google Cloud จะจัดส่ง Swag ให้เราถึงบ้านเลย แต่ส่วนใหญ่ที่มักเจอตามมาคือภาษีนำเข้าจากกรมศุลกากรครับ กรณีนี้ไม่ต้องกลัวครับสามารถจ่ายภาษีนำเข้าพร้อมนำหลักฐาน ส่งอีเมลไปยัง Google ที่ระบุไว้ได้เพื่อเคลมยอดที่เสียไปเข้าบัตรเครดิตครับ ข้อมูลเพิ่มเติม
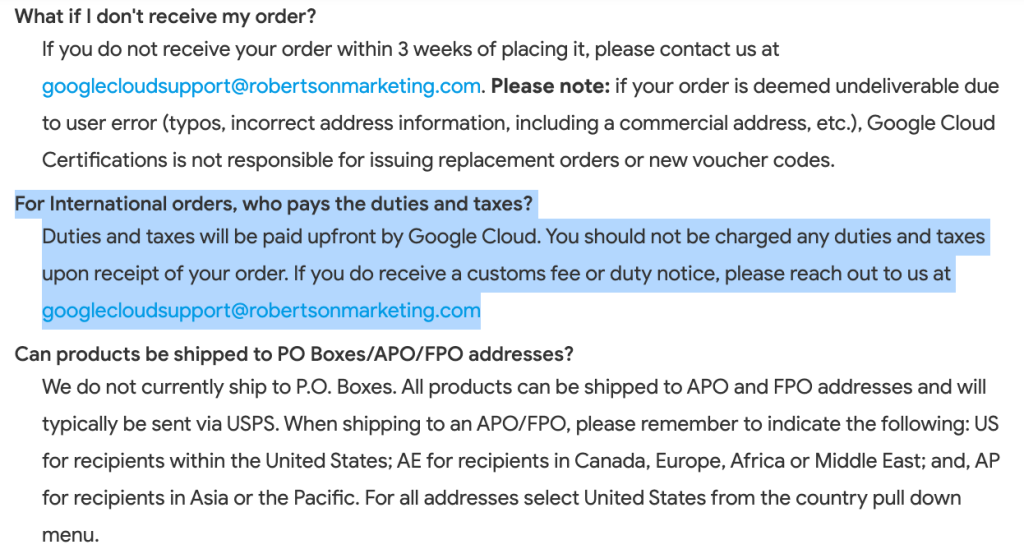
ข้อมูลเพิ่มเติมที่ Help @ Google Merchandise Store
ทำเนียบผู้กล้าบน Credly
เมื่อไม่นานมานี้ผู้เขียนสังเกตว่า Google มีการย้าย Digital Badge & Certificate จาก Accredible ไปที่ Credly ครับ ข้อมูลเราจะไปปรากฏอยู่บน Directory นี้ ทำให้สามารถค้นหาได้ทันทีที่ https://www.credly.com/organizations/google-cloud/directory
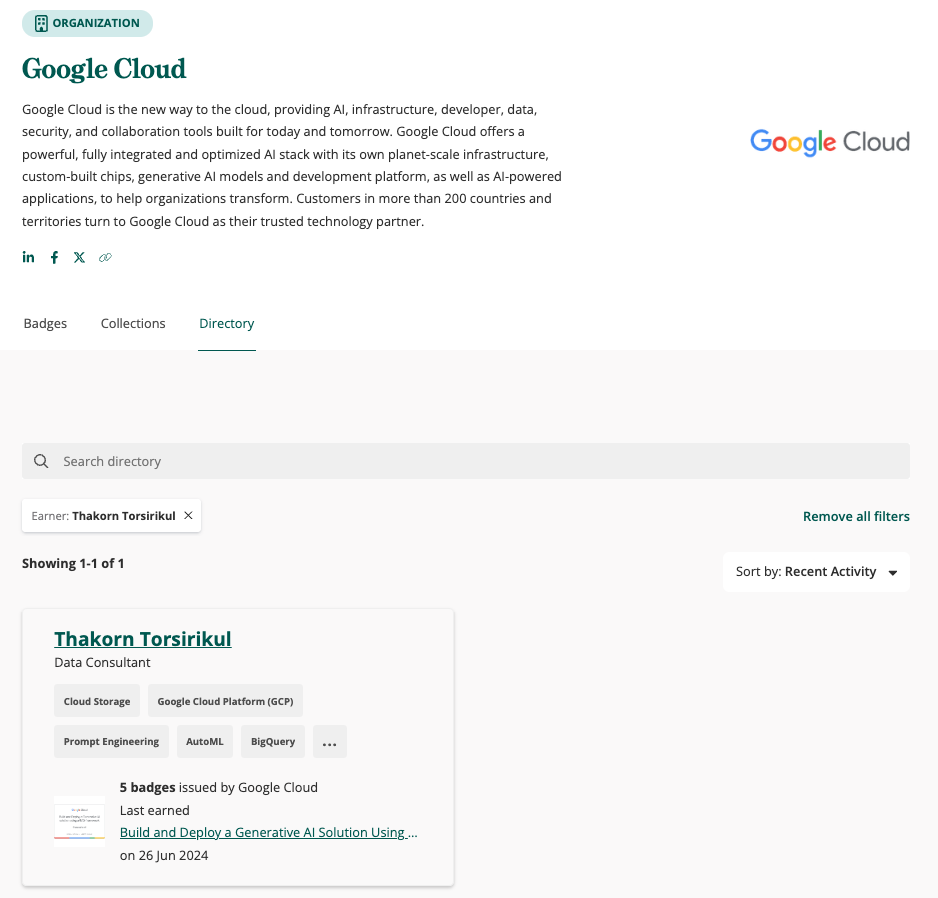
ซึ่ง Portal นี้ทำให้เราค้นหาทั้งของเราและเพื่อน ๆ หรือแม้กระทั่งทีมงานที่เราทำงานด้วยว่า Certificate เหล่านั้นมีจริง Active อยู่ ยังไม่หมดอายุ เพราะว่า Certificate นี้มีอายุจำกัดที่ 2 ปี แต่หากเป็นการ Recertify อย่างผู้เขียน วันหมดอายุก็จะขยายออกไป แต่วันที่ได้รับ Cert ครั้งแรกยังคงเดิมครับ นี่ก็เป็นอีกหนึ่งวิธีที่เราไว้ตรวจสอบข้อมูล
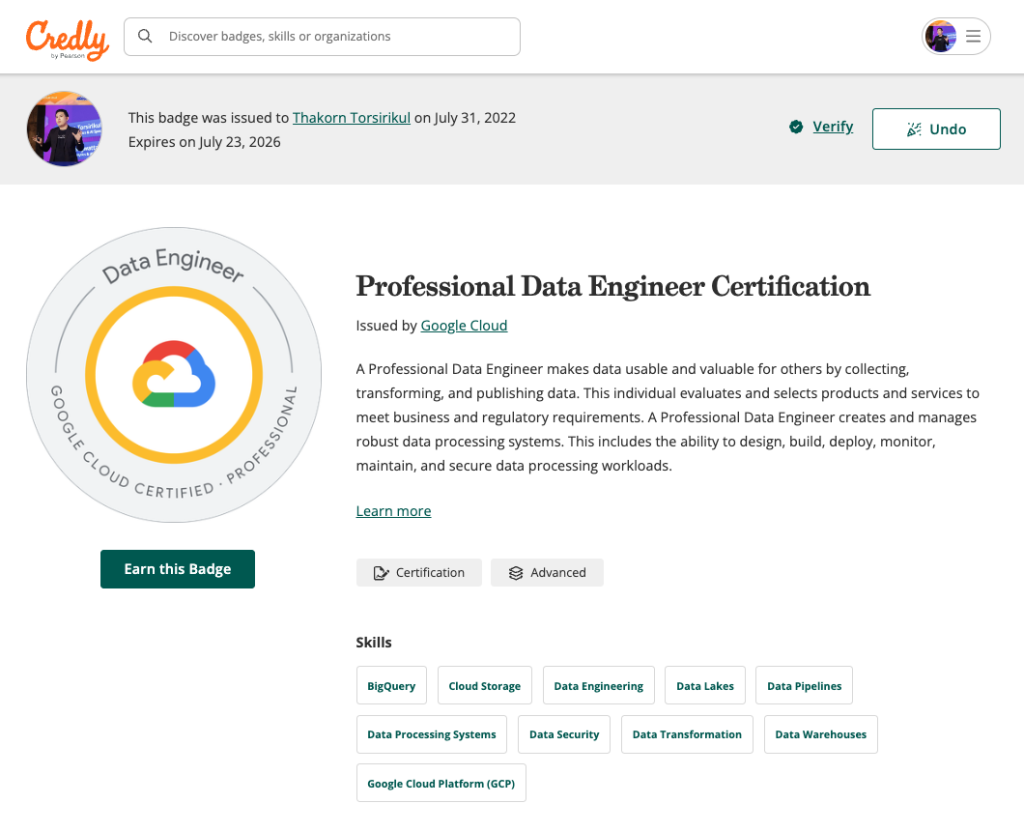
นอกจากนี้เรายังสามารถตรวจสอบได้ว่าปัจจุบัน (2024, July 30) มี Professional Certification ในประเทศไทย Active อยู่กี่ใบได้ ผ่าน Filter เดียวกันครับ สมมติถ้าเป็น Professional Data Engineer ปัจจุบันจะมี 91 ท่าน
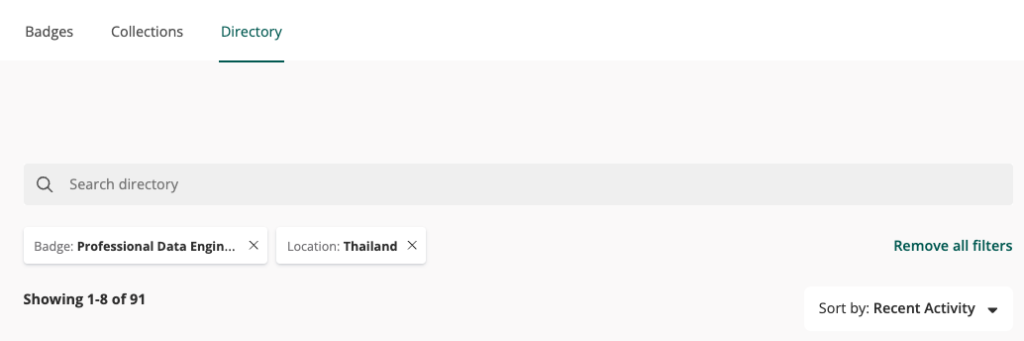
หรือจะดูแบบมี 2 ใบขึ้นไป เช่น เลือก Data Engineering และ Machine Learning ผลลัพธ์การค้นหาก็จะน้อยลงไปอีกเหลือ 21 ท่าน เป็นตัวอย่างประมาณนี้ครับ
ดาวน์โหลดใบประกาศที่ตรงไหน ?
หลายคนอยากได้เป็นใบประกาศใหญ่ ๆ แล้วงงกับระบบ Credly ว่าดาวน์โหลดที่ตรงไหน เดี๋ยวผมจะหาทางลัดพาไปดาวน์โหลดครับ
- เข้าไปที่ลิงก์นี้ https://www.credly.com/earner/earned/badge/
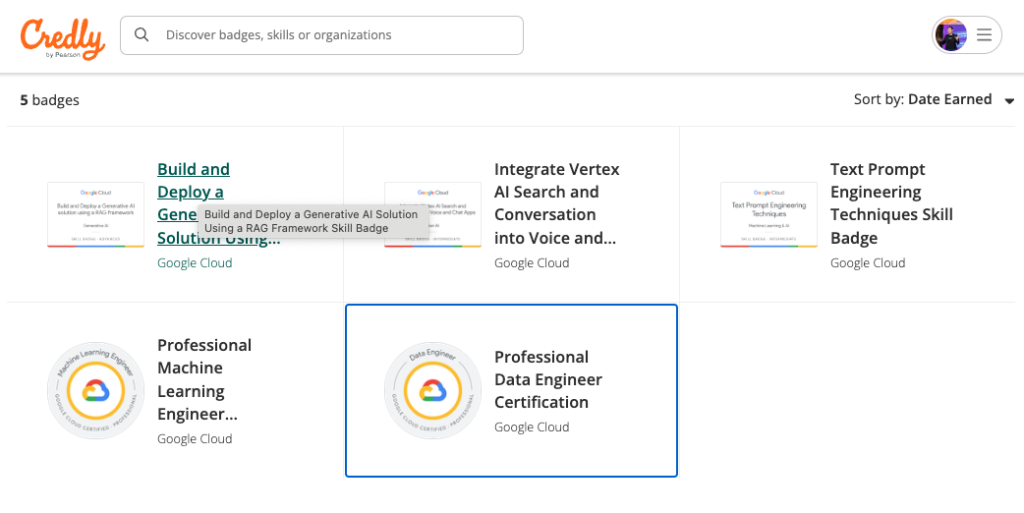
2. เข้าไปที่ Badge ที่เราต้องการแล้วกดตรงปุ่ม Share ขวาบน

3. กด Download Certificate แล้วดาวน์โหลดออกมาเป็น PDF
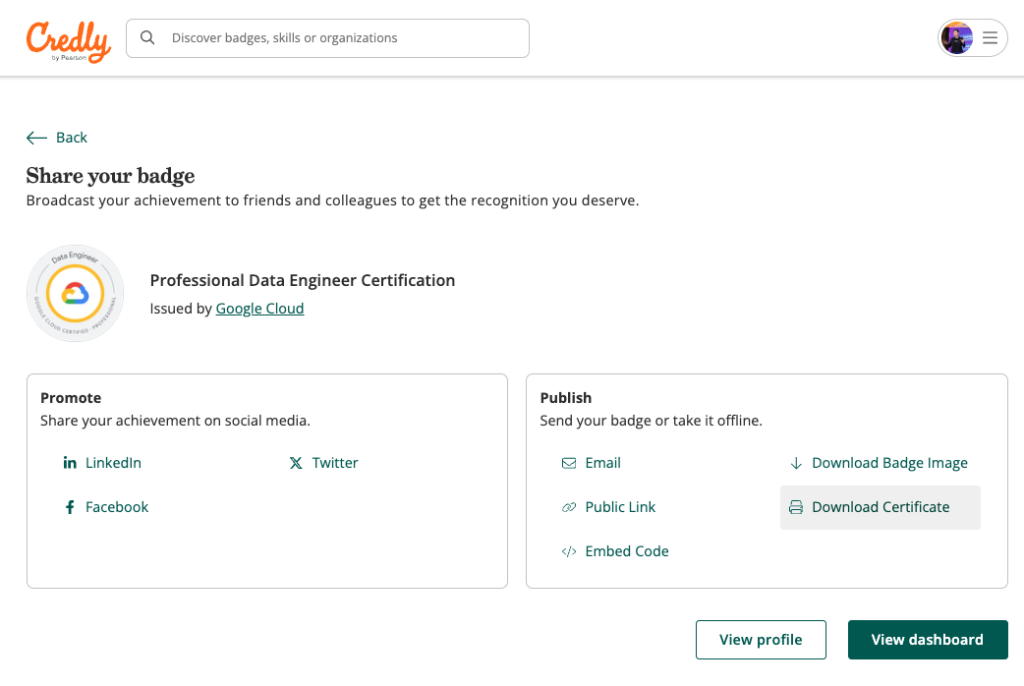
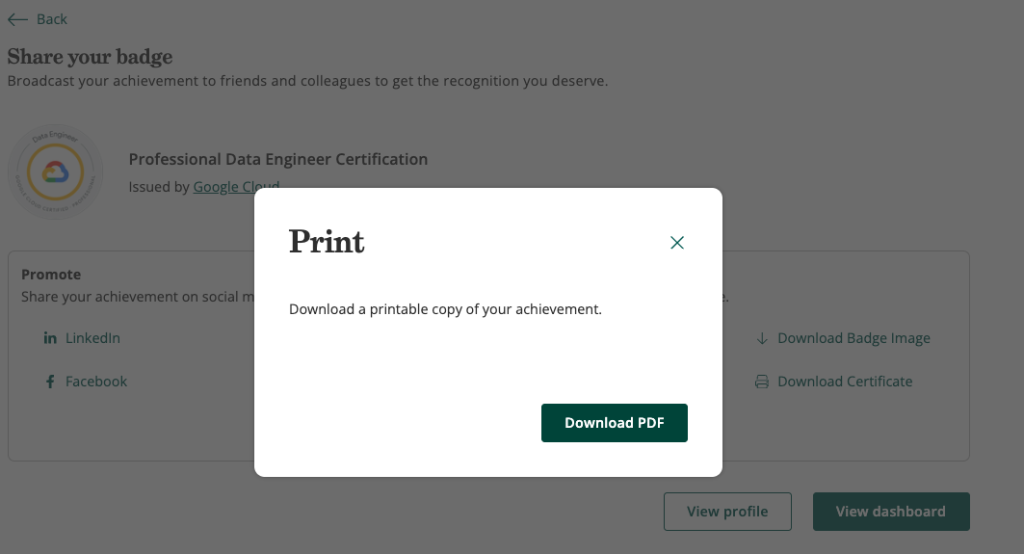
4. จะได้เป็นฉบับเต็มดังภาพครับ

สุดท้ายผมหวังว่าบทความนี้จะเป็นประโยชน์ไม่มากก็น้อยสำหรับผู้ที่จะก้าวเข้าสู่วงการ Google Cloud ในสาย Data นะครับ ไม่ว่าจะเป็น Data Engineer, Data Analyst, Data Scientist หรือจะเป็น Prompt Engineer ก็ดี ขอให้สนุกไปกับเทคโนโลยี และองค์ความรู้ใหม่ ๆ สำหรับวันนี้ผมและทีมงาน Google Cloud by Tangerine ขอลาทุกท่านไปก่อนแล้วพบกันในบทความหน้าครับ
หากท่านสนใจบริการหรือต้องการคำปรึกษาเพิ่มเติม
ติดต่อเราได้ที่ marketing@tangerine.co.th หรือโทร 094 999 4263
ท่านจะได้รับคำตอบจากผู้เชี่ยวชาญที่ได้รับการรับรองมาตรฐาน

